Amazon Berkeley Objects

Amazon Berkeley Objects
Los mercados modernos dependen de la calidad con la que comprenden sus productos. El conjunto Amazon Berkeley Objects (ABO)—826.757 listados con imágenes de alta resolución y metadatos exhaustivos—ofrece una oportunidad poco común para poner a prueba sistemas de reconocimiento visual al ritmo de catálogos reales de comercio electrónico. Este caso práctico detalla cómo audité el dataset, construí una etiqueta fiable de product_type y perfeccioné redes neuronales convolucionales capaces de generalizar entre categorías ruidosas y desbalanceadas.
Dataset: Amazon Berkeley Objects
Objetivo
El objetivo es entrenar una red convolucional que infiera atributos del producto—marca, color, tipo y otras señales comerciales—directamente a partir de imágenes. Para lograrlo fue necesario repensar a fondo las tablas originales de ABO. Tras unificar las fuentes siguen existiendo 826.757 filas, listados duplicados y una gran escasez en la mayoría de los campos descriptivos.
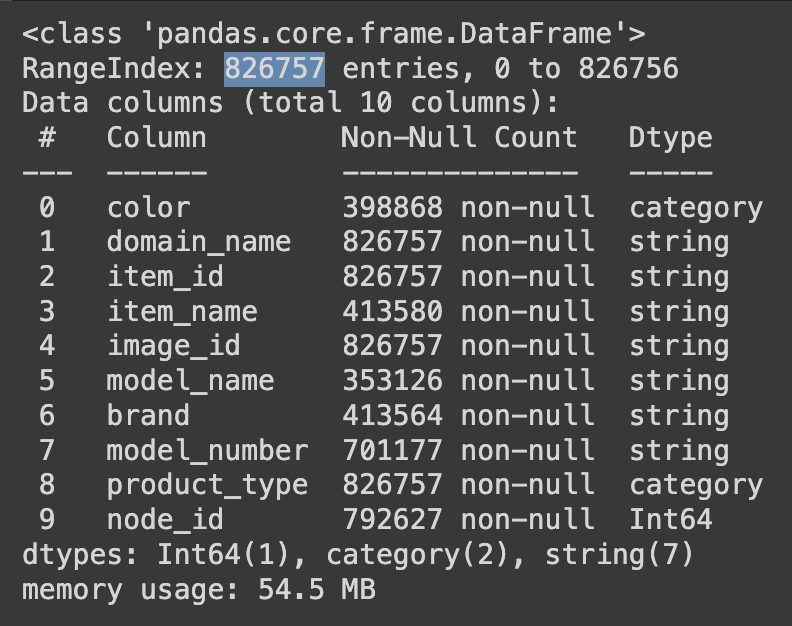
El mapa de valores nulos muestra por qué conviene elegir bien la etiqueta. Campos como product_type y node_id están casi completos, mientras que brand y colour presentan enormes agujeros. Lo importante es que los faltantes no coinciden fila a fila: un registro puede tener color pero no marca y el siguiente justo lo contrario. Predecir múltiples objetivos exigiría, por tanto, pipelines de preprocesamiento específicos para cada atributo—equilibrar clases, imputar o agrupar categorías y normalizar vocabularios de etiquetas. Para mantener el artículo enfocado, describo todo el flujo solo para product_type; después repliqué la estrategia en los demás atributos.
Conjunto de metadatos
ABO combina atributos comerciales estructurados con imágenes sin procesar. Entender qué columnas son fiables desde el inicio fue clave para definir etiquetas y variables auxiliares.
- Datos estructurados (Listings): archivos CSV normalizados con descripciones, identificadores categóricos y otros atributos del catálogo.
- Datos no estructurados: el archivo de imágenes, que necesita uniones por ruta y transformaciones espaciales antes de alimentar a una CNN.
Columnas principales del listado:
item_id(nominal): identificador único del producto en el catálogo.domain_name(nominal): marketplace de origen, útil para evaluar cambios de dominio.item_name(nominal): título del producto en varios idiomas.3dmodel_id(nominal): identificador del modelo 3D cuando está disponible.brand(nominal): nombre de la marca en múltiples idiomas.bullet_point(nominal): puntos de marketing, generalmente multilingües.colour(nominal): descripción del color más paleta estandarizada.colour_code(nominal): codificación hexadecimal del color.country(nominal): código de país ISO 3166-1 del listado.item_dimensions(numérico): alto, largo y ancho en pulgadas.item_weight(numérico): peso en libras.main_image_id(nominal): identificador de la imagen principal.marketplace(nominal): plataforma donde se vende el artículo.material(nominal): descripción del material principal.model_number(nominal): referencia del fabricante.node(nominal): ruta jerárquica de categorías proporcionada por Amazon.other_image_id(nominal): identificadores de vistas secundarias.product_type(nominal): taxonomía canónica utilizada como objetivo en este estudio.spin_id(nominal): identificador de inventario.
El metadato Images-Small enlaza las imágenes con los listados:
image_id(nominal): unión conmain_image_id/other_image_id.heightywidth(numérico): dimensiones en píxeles, clave para las estrategias de redimensionado.path(nominal): ruta relativa del recurso.
Muchas columnas exigieron limpieza profunda y solo un subconjunto alimentó a los modelos finales.
Arquitectura
Todos los experimentos se ejecutaron de forma local, así que la selección de modelos equilibró precisión y costo de entrenamiento. El punto de partida usa CNN preentrenadas en ImageNet que pueden reajustarse rápido sin desbordar la memoria de la GPU.
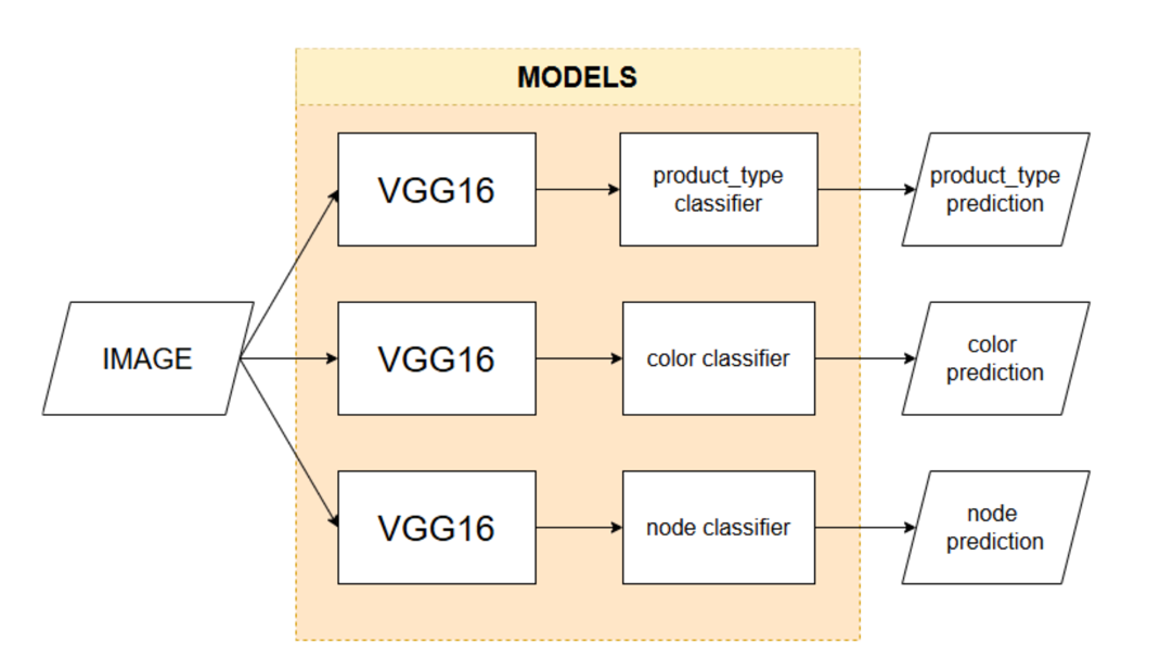
La auditoría de preprocesamiento mostró que cada atributo objetivo se comporta distinto: patrones de ausencia, desbalance y vocabularios varían bastante. Entrenar modelos específicos por atributo evita transferencias negativas entre objetivos y permite ajustar para cada pipeline la mejor combinación de aumentos, balanceo y configuración de pérdida. VGG16 fue el caballo de batalla porque su campo receptivo se adapta bien a las imágenes redimensionadas y se ajusta con estabilidad en hardware de consumo. El costo es mayor tiempo total de entrenamiento, pero la ganancia es una convergencia más limpia por atributo.
Arquitectura alternativa: B-CNN
Los Bilayer CNN (B-CNN) también se evaluaron a nivel conceptual para respetar la señal jerárquica presente en la taxonomía node. La idea es escalonar las predicciones de lo general a lo específico: primero una familia amplia (por ejemplo, Furniture) y luego especializar (Office Chair). Con este enfoque, los errores se mantienen cercanos semánticamente—confundir una silla con un escritorio es aceptable, hacerlo con un mouse no. La función de pérdida propuesta en el paper de B-CNN penaliza los saltos grandes en la jerarquía, empujando a la red a refinar la predicción en cada etapa.
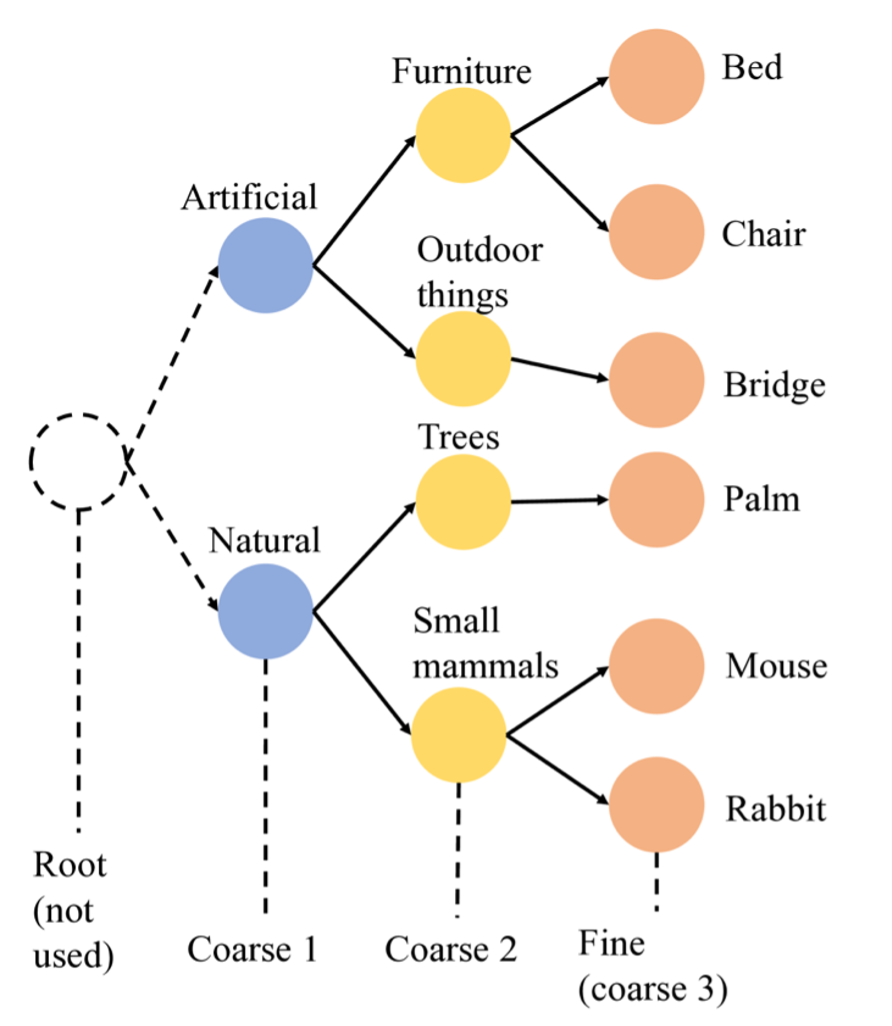
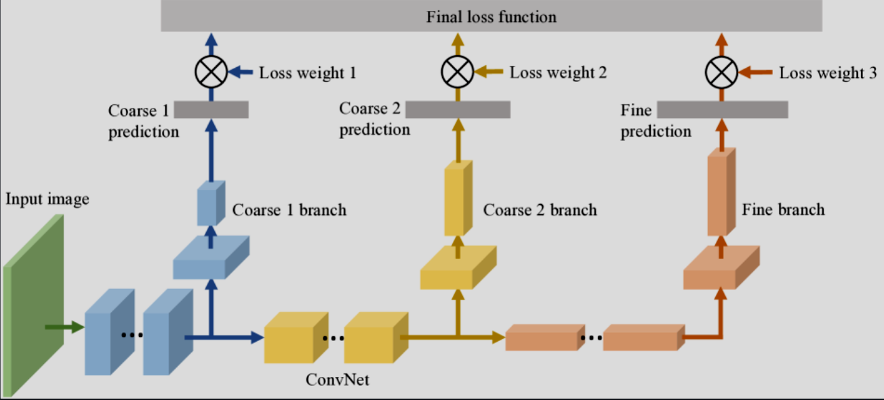
En la práctica la taxonomía original resultó demasiado inconsistente para montar una jerarquía limpia.
Varios caminos parten de raíces diferentes, mezclan idiomas o cambian de profundidad, lo que dificulta garantizar relaciones padre-hijo coherentes. Aun después de invertir bastante tiempo limpiando esta columna, el ruido superó las posibles ganancias, así que quedó como trabajo futuro.
Preprocesamiento
El recorrido se centra en product_type. Después repliqué los mismos patrones de limpieza y balanceo para los otros atributos objetivo.
Solo incluyo los fragmentos de código más ilustrativos.
Unificación de metadatos
Tras descartar columnas de bajo valor, la metadata de listings se consolidó en un único dataframe. Trabajar con una tabla canónica simplificó uniones posteriores, auditorías de faltantes y chequeos de integridad.
Valores faltantes y datos duplicados
Eliminar registros de imágenes duplicadas evitó sesgos en la distribución de entrenamiento. Propagué los atributos a las imágenes primarias y secundarias para que cada muestra conserve un paquete de etiquetas coherente.
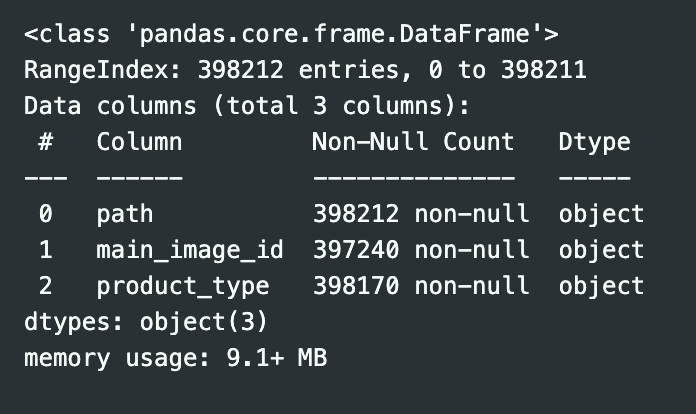
1
merged_df.info()
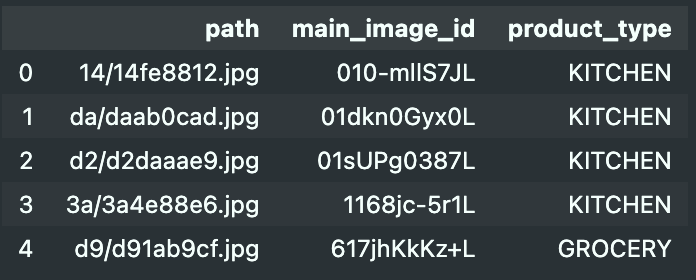
1
merged_df.head()
Preparación de etiquetas
El campo original product_type contiene 512 valores con una distribución fuertemente sesgada. Entrenar directamente sobre ese desbalance lleva a que la red sobreajuste las categorías predominantes del hogar.
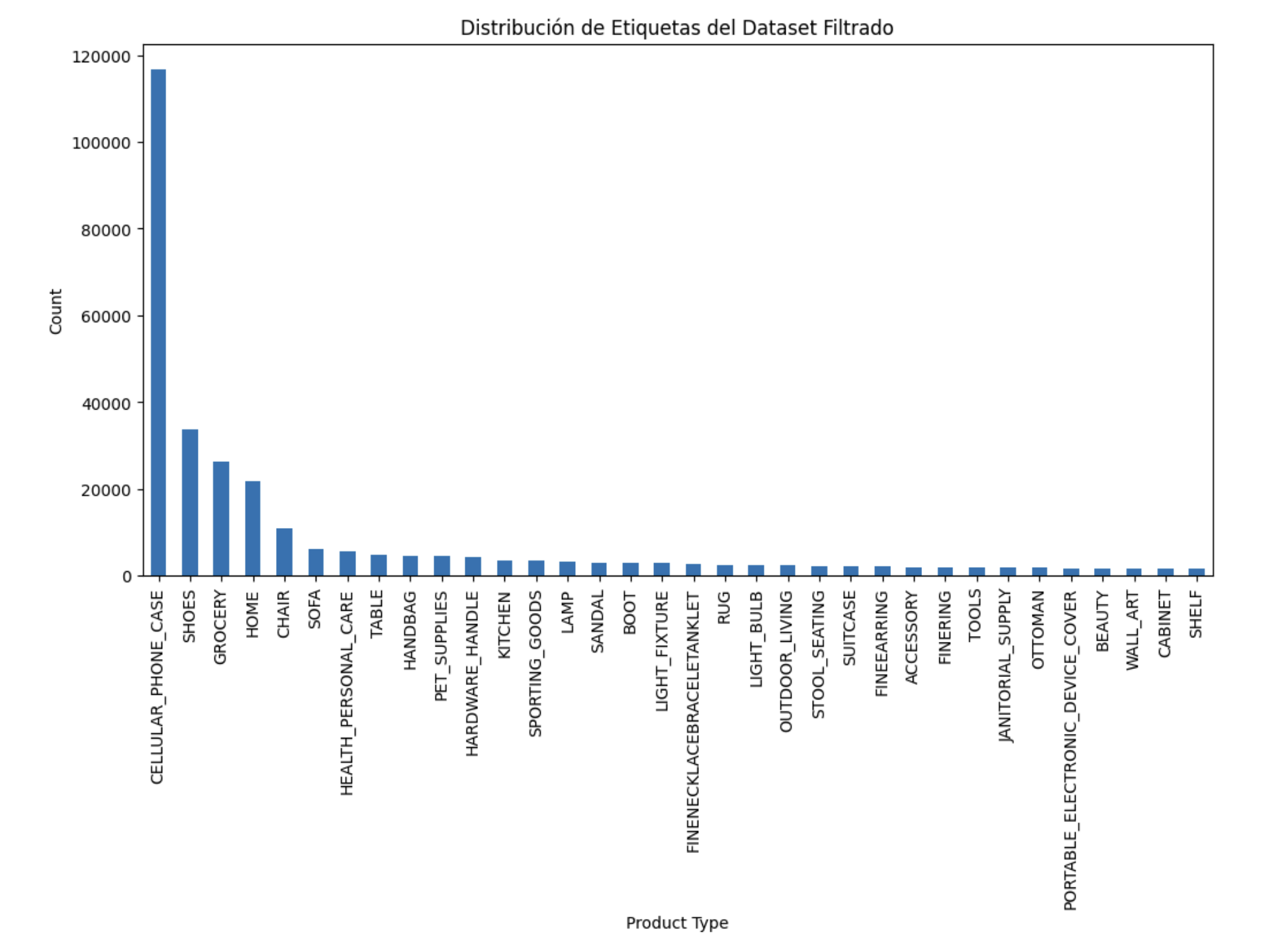
Dos medidas ayudaron a mitigar el problema:
- Limitar a 2.000 el número de imágenes por clase para reducir el dominio de las categorías mayoritarias manteniendo diversidad suficiente.
- Colapsar o eliminar categorías ambiguas. Etiquetas como
homeogroceryse solapaban con clases más específicas, así que las fusioné en grupos más claros (por ejemplo, el calzado quedó bajoBoots,ShoesySandal).
Incluso con estas intervenciones, el trabajo siguió siendo exigente en recursos. Todas las iteraciones se entrenaron en una workstation local (Intel i7-12700K, NVIDIA RTX 3060 Ti, 32 GB DDR5) y cada experimento demandó cerca de 400 minutos. La mayoría de los entrenamientos corrían de noche mientras durante el día ajustaba curación de etiquetas y aumentos.
Iteraciones del modelo
Siete iteraciones exploraron distintas arquitecturas, estrategias de fine-tuning y técnicas de regularización. Las notas resumen qué cambió, cómo afectó a las métricas de validación y por qué se abandonaron ciertos caminos.
Iteración V1 VGG16
El primer baseline utilizó VGG16 ajustado sobre 42 clases, cada una limitada a 2.000 imágenes. Adam con una tasa de 0,01 impulsó el entrenamiento mientras las capas convolucionales quedaron congeladas durante las 20 primeras épocas. Tras ese warm-up se desbloquearon las últimas 20 capas para aplicar fine-tuning progresivo. Aunque la documentación de ABO promete imágenes de 256×256, la mayoría son más pequeñas, así que se redimensionaron a 224×224 para alinearse con la resolución nativa de VGG16.
Loss en validación: 1.2007800340652466
Accuracy en validación: 0.6813859939575195
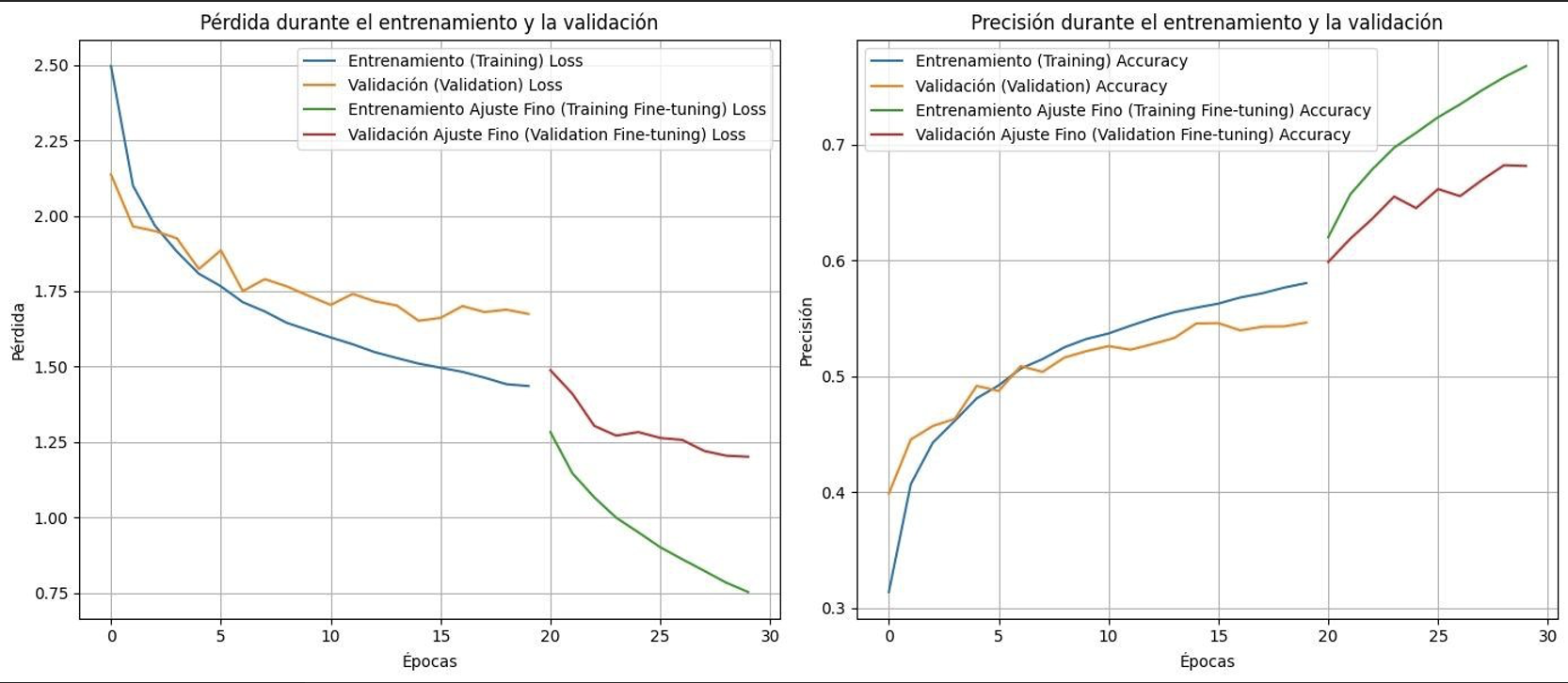
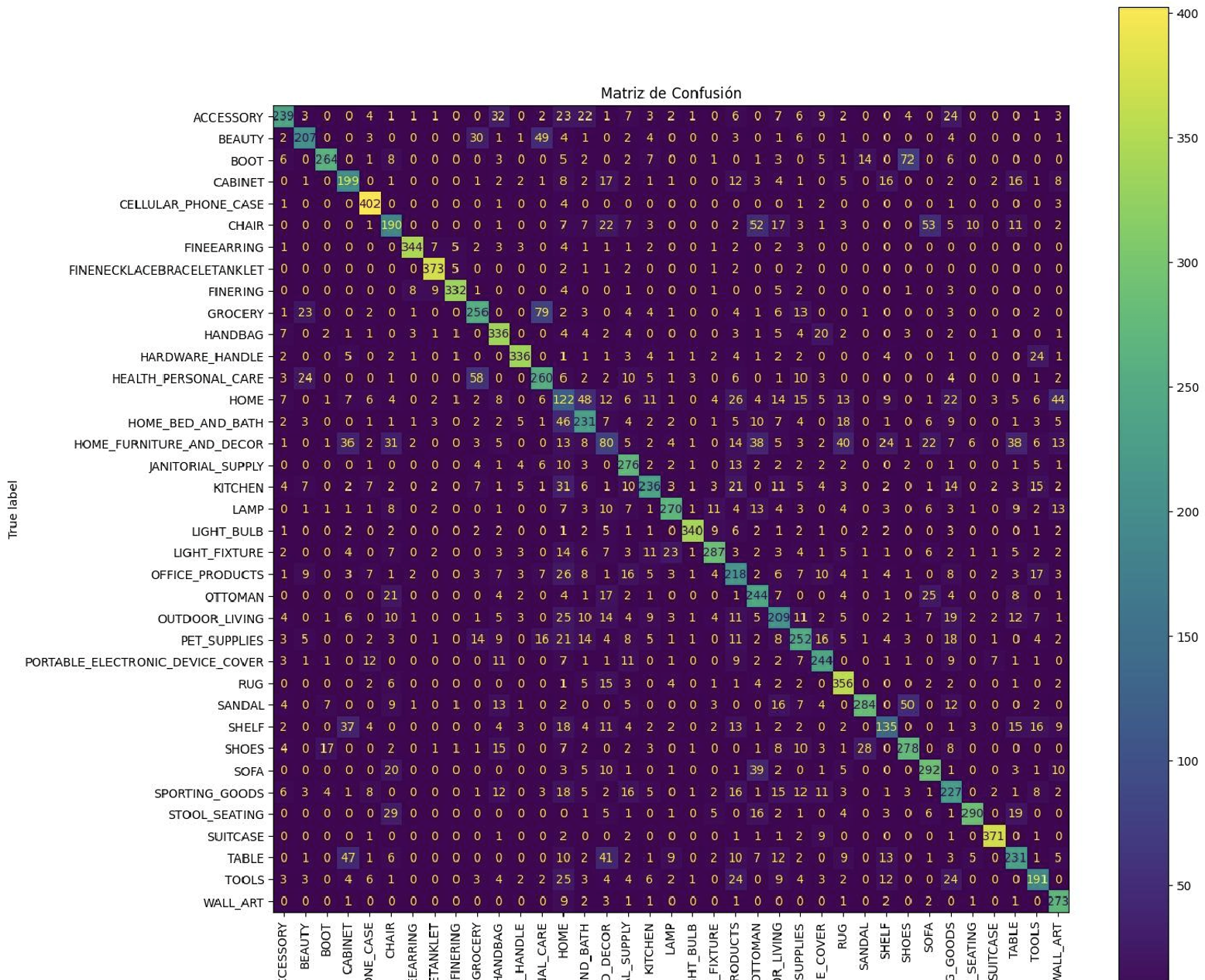
La accuracy de validación rondó el 70%, confirmando que el setup era viable. La matriz de confusión ya evidenciaba el problema de las etiquetas muy amplias (errores entre clases con solape), así que la siguiente iteración se concentró en la regularización.
Iteración V2 VGG16
La segunda iteración mantuvo VGG16 pero afinó el ciclo de entrenamiento. Incorporé early stopping y checkpoints para acortar corridas poco productivas, y ajusté el calendario de fine-tuning para desbloquear capas de forma más gradual. La data augmentation—flips, traslaciones, zooms y cambios de brillo—amplió el tamaño efectivo del dataset:

Resultados:
Loss en validación: 0.899906396865844
Accuracy en validación: 0.7329152822494507
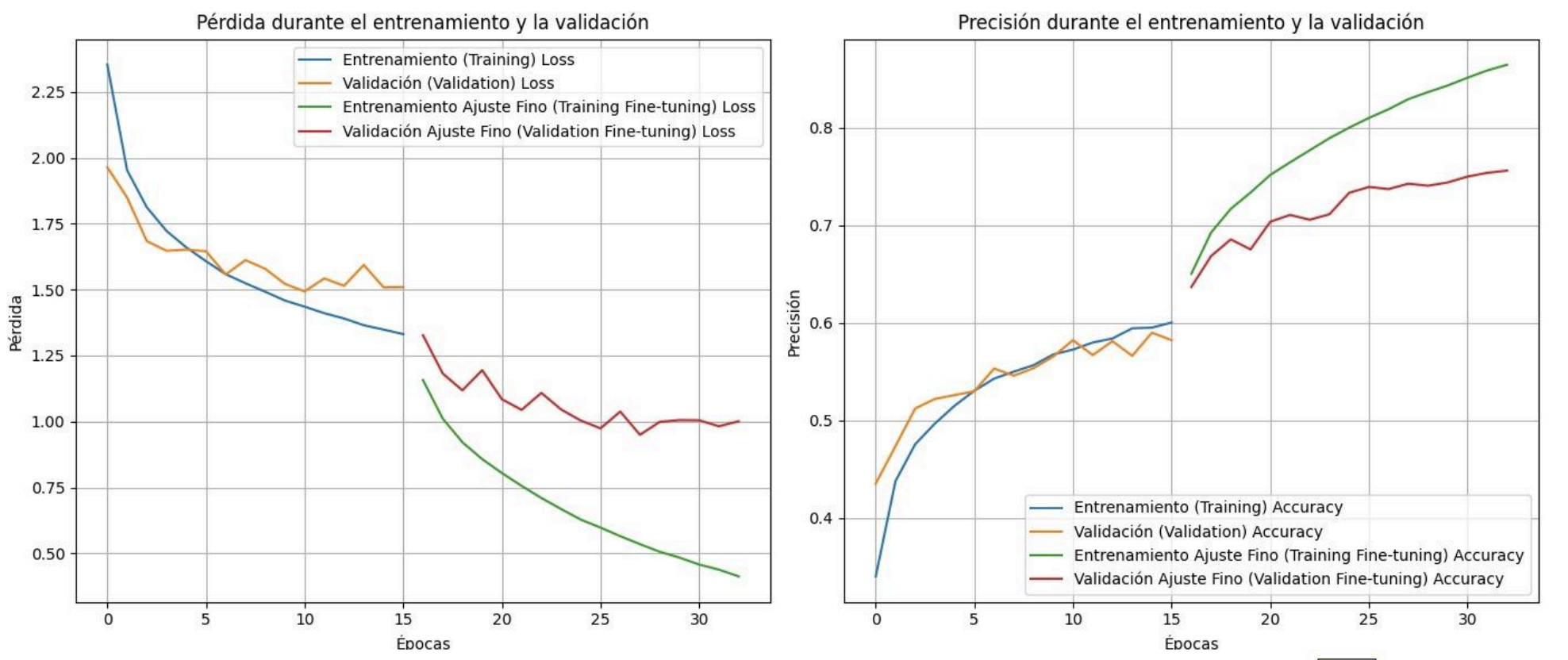
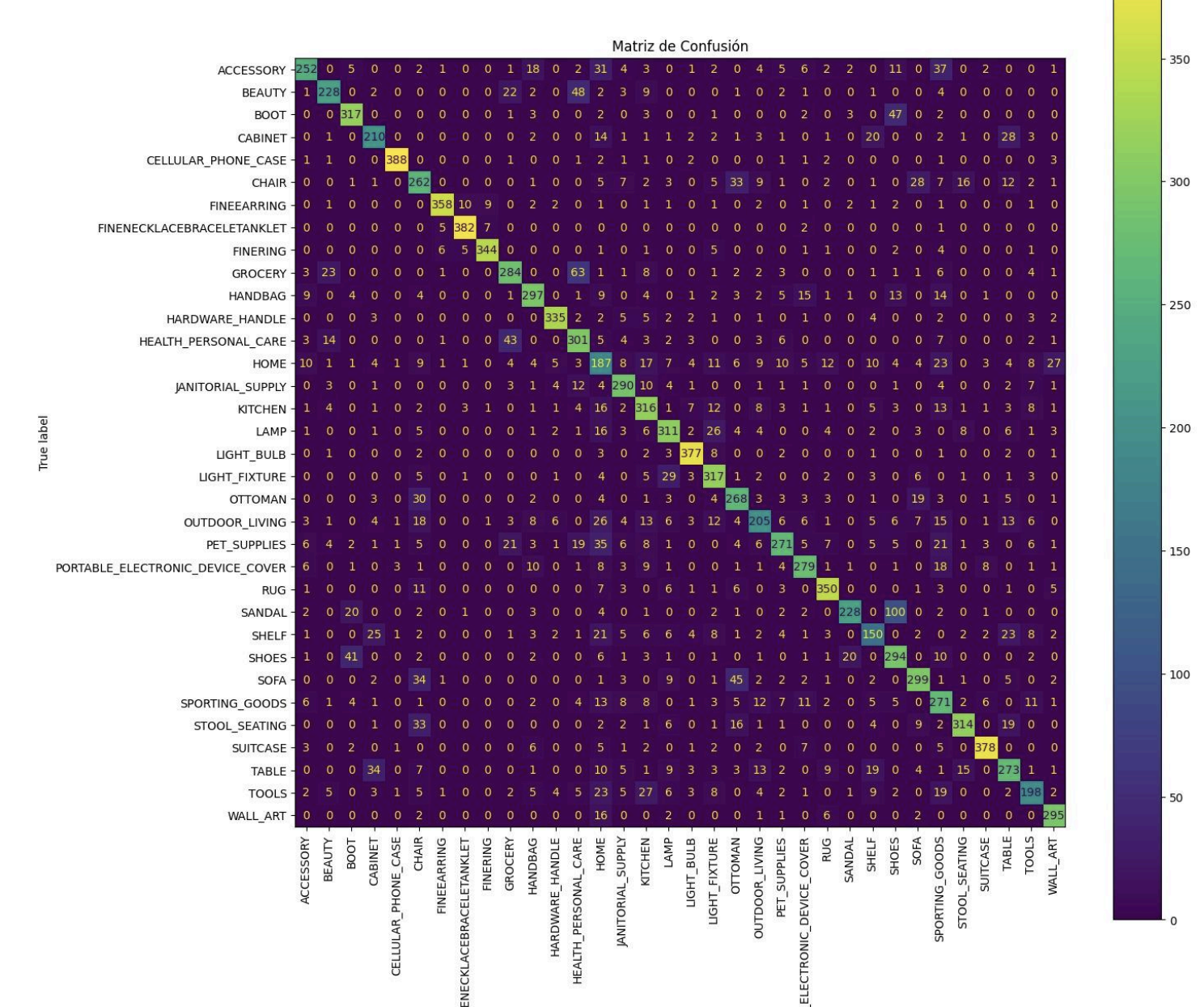
El fine-tuning progresivo marcó la diferencia: la accuracy superó el 73%, aunque al desbloquear capas profundas apareció divergencia entre entrenamiento y validación. Las siguientes pruebas se centraron en ese sobreajuste.
Iteración V3 ResNet50
ResNet50 fue el primer intento de escalar al tamaño completo de 256×256 sin fine-tuning progresivo. El entrenamiento se volvió lento e inestable; tras 30 épocas la accuracy quedó estancada alrededor del 29%, por lo que detuve el experimento. El cambio de arquitectura dejó claro que profundizar la red no resuelve el ruido y el desbalance en las etiquetas.
Iteración V4 InceptionV3
Para recuperar velocidad, la siguiente prueba cambió a InceptionV3 y redimensionó las entradas a 299×299 para ajustarse a la arquitectura. Es más ligera que ResNet y maneja bien features multi-escala.
- Loss en validación: 0.8999063968658447
- Accuracy en validación: 0.7329152822494507
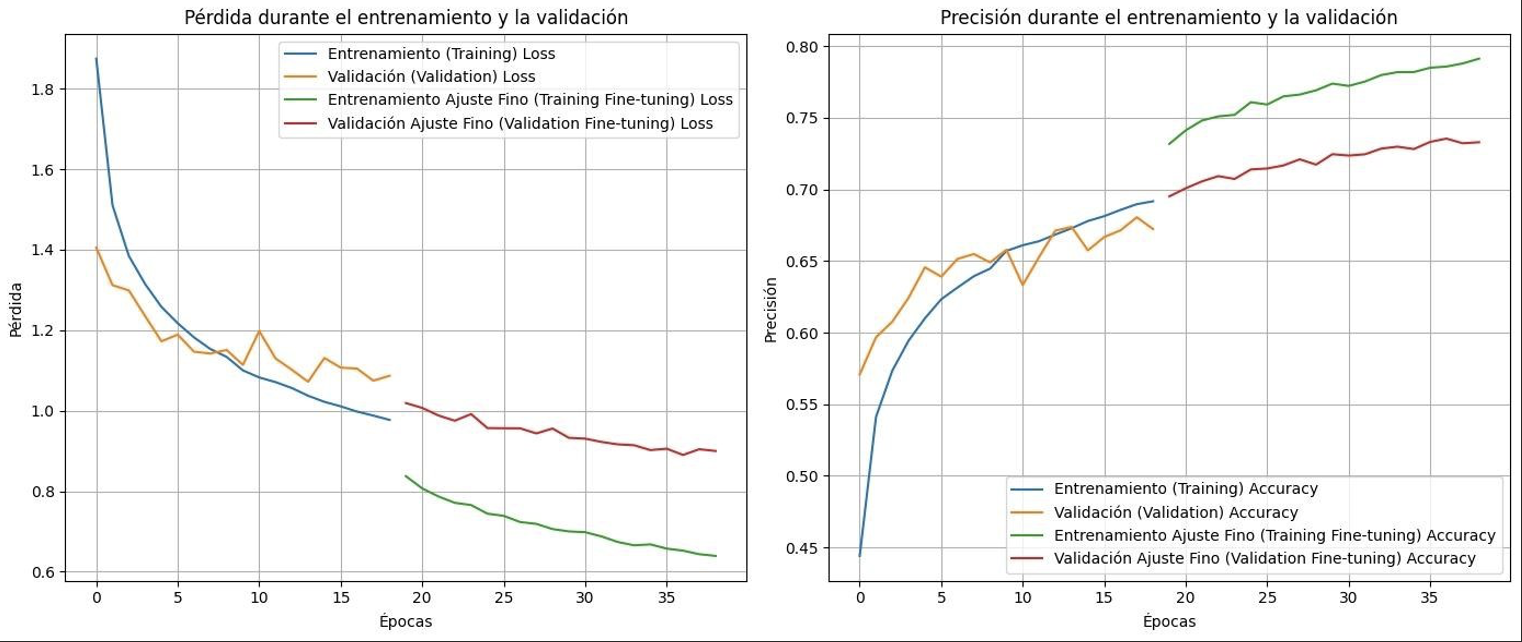
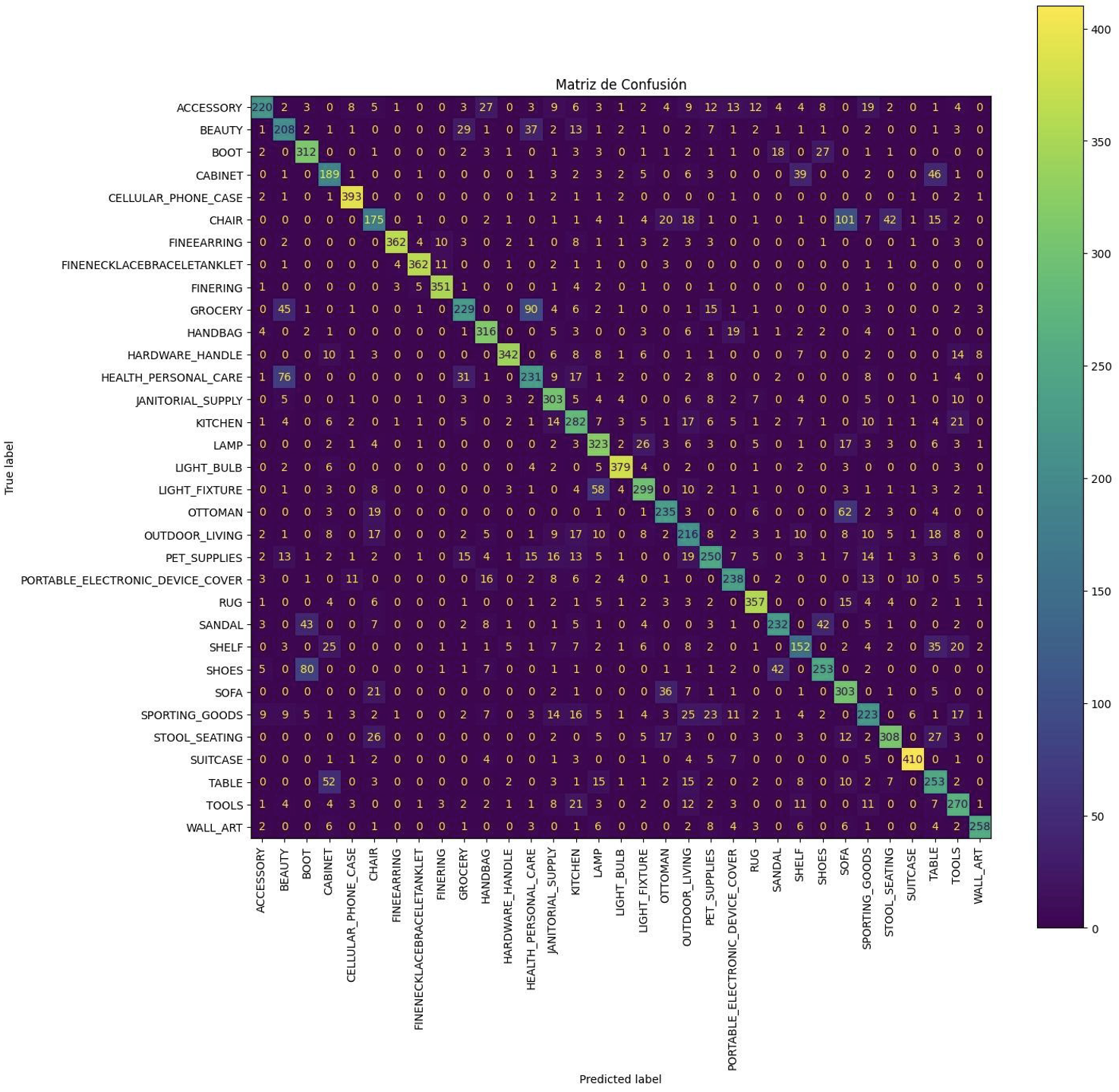
La accuracy se mantuvo competitiva, pero el sobreajuste persistió. A partir de aquí preferí regularizar los backbones VGG en lugar de seguir cambiando de arquitectura.
Iteración V5 VGG16
Dado el buen comportamiento previo de VGG16, la quinta iteración volvió a ese backbone pero entrenó con recortes completos de 256×256. El peso de L2 sustituyó al dropout como regularizador principal y se desactivó el fine-tuning progresivo para comprobar si la actualización temprana de capas controlaba el sobreajuste. Tras 50 épocas la accuracy de validación se estancó en 43%, probablemente por una tasa de aprendizaje demasiado alta—las curvas mejoraron muy poco durante casi toda la corrida—, así que detuve el experimento.
Iteración V6 VGG16
Con poco tiempo restante, la iteración final combinó los mejores elementos anteriores: VGG16 sobre entradas de 256×256, fine-tuning progresivo con desbloqueo a mitad de entrenamiento y dropout (0,3) para regularizar la cabeza clasificadora. Adam volvió con el mismo schedule de aprendizaje que la V2 y las etiquetas se ajustaron de nuevo para reducir categorías ambiguas.
- Loss en validación: 1.32392418384552
- Accuracy en validación: 0.6500535607337952
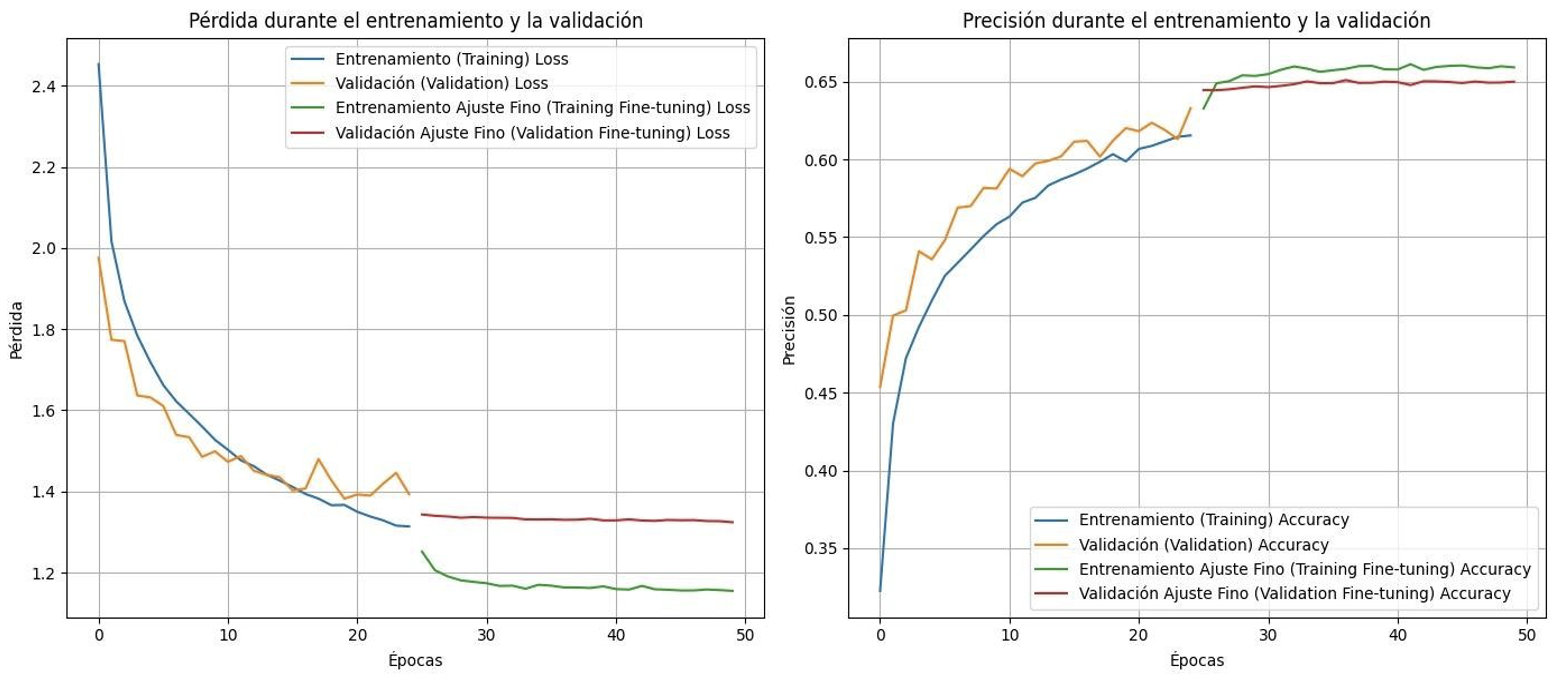
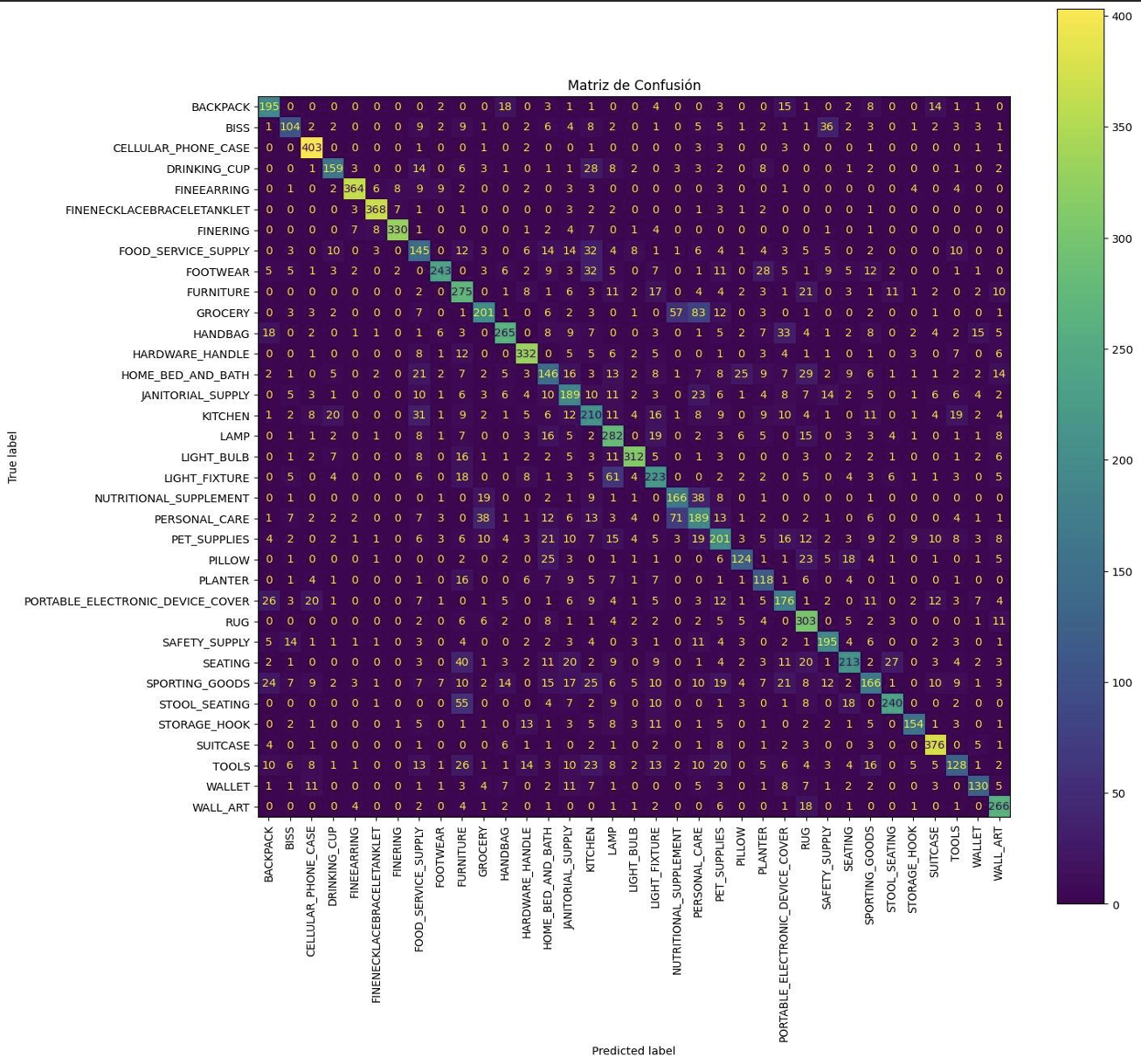
Esta corrida por fin domó el sobreajuste, aunque la accuracy quedó en 65%. Cada experimento reforzó la idea de que la higiene de etiquetas impulsa el desempeño tanto como los ajustes arquitecturales. El entrenamiento siguió siendo costoso—entre 6 y 8 horas por corrida en hardware local—, por lo que las próximas mejoras vendrán de consolidar mejor las etiquetas y equilibrar clases antes de cambiar nuevamente de red.
Conclusión
ABO es un benchmark exigente porque el éxito depende de la calidad de los datos tanto como de la profundidad del modelo. La mejor configuración combinó preprocesamiento agresivo, curación de etiquetas, data augmentation y fine-tuning progresivo para alcanzar 73% de accuracy en validación, mientras que iteraciones posteriores sacrificaron precisión a cambio de mayor generalización. El desbalance, los duplicados y la taxonomía inconsistente fueron los principales obstáculos.
El trabajo futuro pasa por depurar aún más la jerarquía de etiquetas, experimentar con arquitecturas alternativas (por ejemplo, B-CNN o modelos de detección) y escalar el entrenamiento con hardware en la nube para explorar calendarios más largos sin perder velocidad de iteración.
Video demo (Iteración V2):
Notebook (Iteración V2):
https://drive.google.com/file/d/1EjAnTSAilT7ZBMa9Izb3IaRqN7fAeIJJ/view?usp=sharing