San Francisco Crime Classification

Contexto
San Francisco es reconocida por su diversidad cultural, innovación tecnológica y, lamentablemente, por un pasado con altos índices delictivos. Analizar datos de criminalidad no solo aporta contexto histórico, también revela patrones y tendencias que ayudan a comprender mejor la dinámica de los delitos en la ciudad. En este caso, disponemos de un dataset cuidadosamente recopilado que cubre el periodo 2003-2015, ofreciendo una radiografía detallada de más de una década de incidentes.
Este registro masivo permite estudiar cómo evolucionó el crimen en un momento de profundos cambios socioeconómicos y culturales. La expansión tecnológica, los desafíos habitacionales y la complejidad del entramado social se reflejan en las cifras. Tras revisar distintos artículos sobre la situación en San Francisco, destaco algunos puntos:
- Una de cada dieciséis personas es víctima de un delito contra la propiedad o de violencia, lo que convierte a la ciudad en más peligrosa que el 98% de las urbes estadounidenses. Para dimensionarlo, Compton (California), famosa por sus conflictos entre bandas y todavía más peligrosa que el 90% de las ciudades del país, es casi el doble de segura que San Francisco.
- El cuerpo policial enfrenta dificultades estructurales. En comparación con Nueva York u otras metrópolis, San Francisco tiene menos agentes per cápita, una brecha que impacta en la eficacia para contener el delito.
Con este contexto, podemos profundizar en los atributos del dataset.
Campos de datos
- Dates: fecha y hora del incidente.
- Category: categoría del delito (solo en
train.csv). Es la variable objetivo. - Descript: descripción detallada del incidente (solo en
train.csv). - DayOfWeek: día de la semana.
- PdDistrict: distrito policial.
- Resolution: resolución del incidente (solo en
train.csv). - Address: dirección aproximada del hecho.
- X: longitud.
- Y: latitud.
Datos de entrada
Realizo las importaciones necesarias:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
!pip install geoplot
!pip install contextily
!pip install eli5
!pip install pdpbox
!pip install --upgrade pdpbox
!pip install shap
## --
import pandas as pd
from shapely.geometry import Point
import geopandas as gpd
import matplotlib.pyplot as plt
import numpy as np
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
import seaborn as sns
from matplotlib import cm
import urllib.request
import shutil
import zipfile
import os
import re
import contextily as ctx
import geoplot as gplt
#from pdpbox import get_dataset
import lightgbm as lgb
import eli5
from eli5.sklearn import PermutationImportance
from lightgbm import LGBMClassifier
from matplotlib import pyplot as plt
from pdpbox import pdp, info_plots
import shap
Divido el dataset en train y test e inspecciono las primeras filas:
1
2
3
4
train = pd.read_csv('train.csv', parse_dates=['Dates'])
test = pd.read_csv('test.csv', parse_dates=['Dates'], index_col='Id')
train.head()

Visualización de datos
Algunas visualizaciones se generaron en RapidMiner por comodidad.
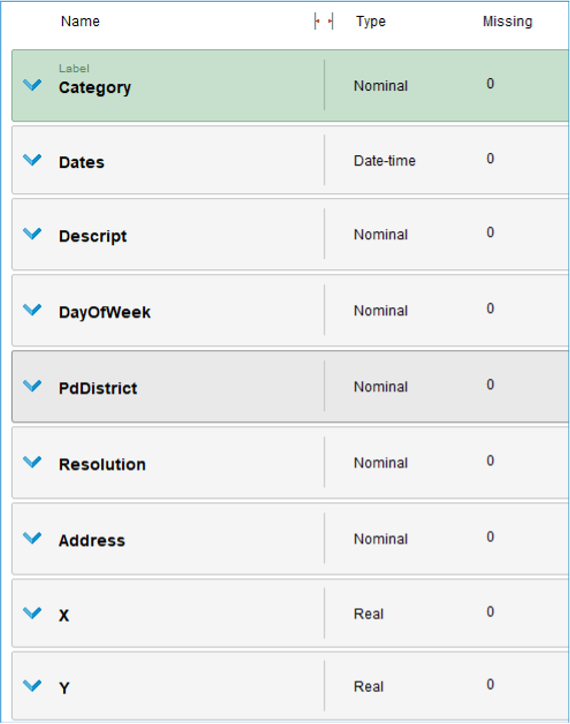
Para familiarizarnos con el dataset conviene revisar la distribución de los atributos. El problema puede abordarse con métodos supervisados (contamos con la etiqueta objetivo), pero también sería posible aplicar enfoques no supervisados y agrupar por ubicación, horario o distrito.
El conjunto de entrenamiento contiene 878.049 registros entre 2003 y 2015 sin valores faltantes. Predominan los atributos nominales, salvo las coordenadas. Veamos los campos con más detalle.
Category
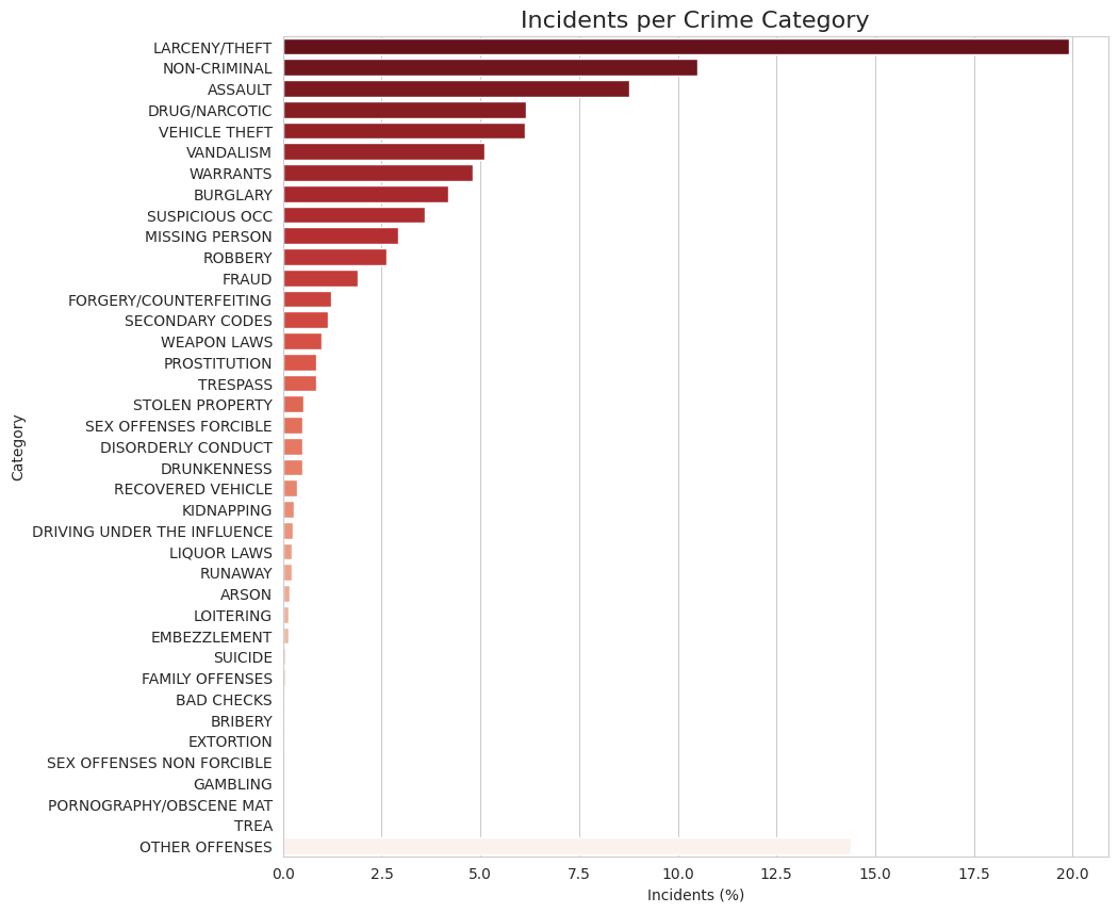
La variable objetivo es nominal y extremadamente desbalanceada: casi 180.000 filas pertenecen a “Larceny/Theft”, mientras que la mayoría de las categorías no supera las 8.000 filas. Esto puede provocar sobreajuste si no se corrige. Algunas estrategias posibles:
- Conservar todas las categorías, aceptando la complejidad.
- Agrupar categorías relacionadas para reducir el número total de clases.
- Quedarnos con un subconjunto de delitos predominantes en la ciudad.
Date
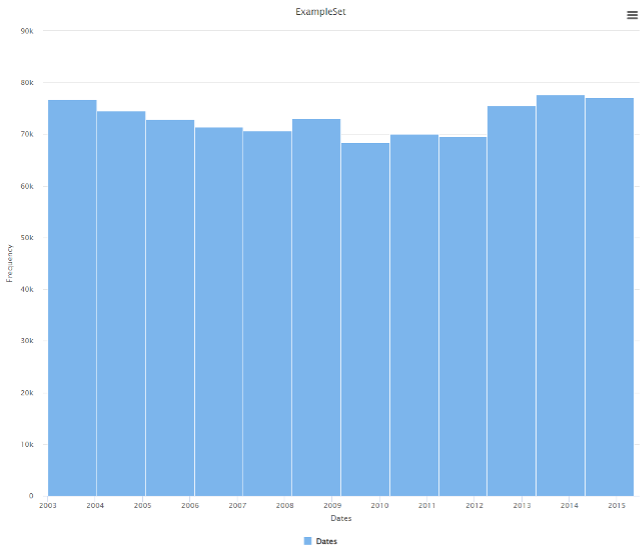
La serie temporal revela que la cantidad anual de delitos se mantiene estable durante los 12 años analizados, lo que muestra poca mejora estructural. Dado que “Date” es un datetime, conviene derivar nuevas variables (año, mes, día, hora) para capturar patrones finos.
PdDistrict
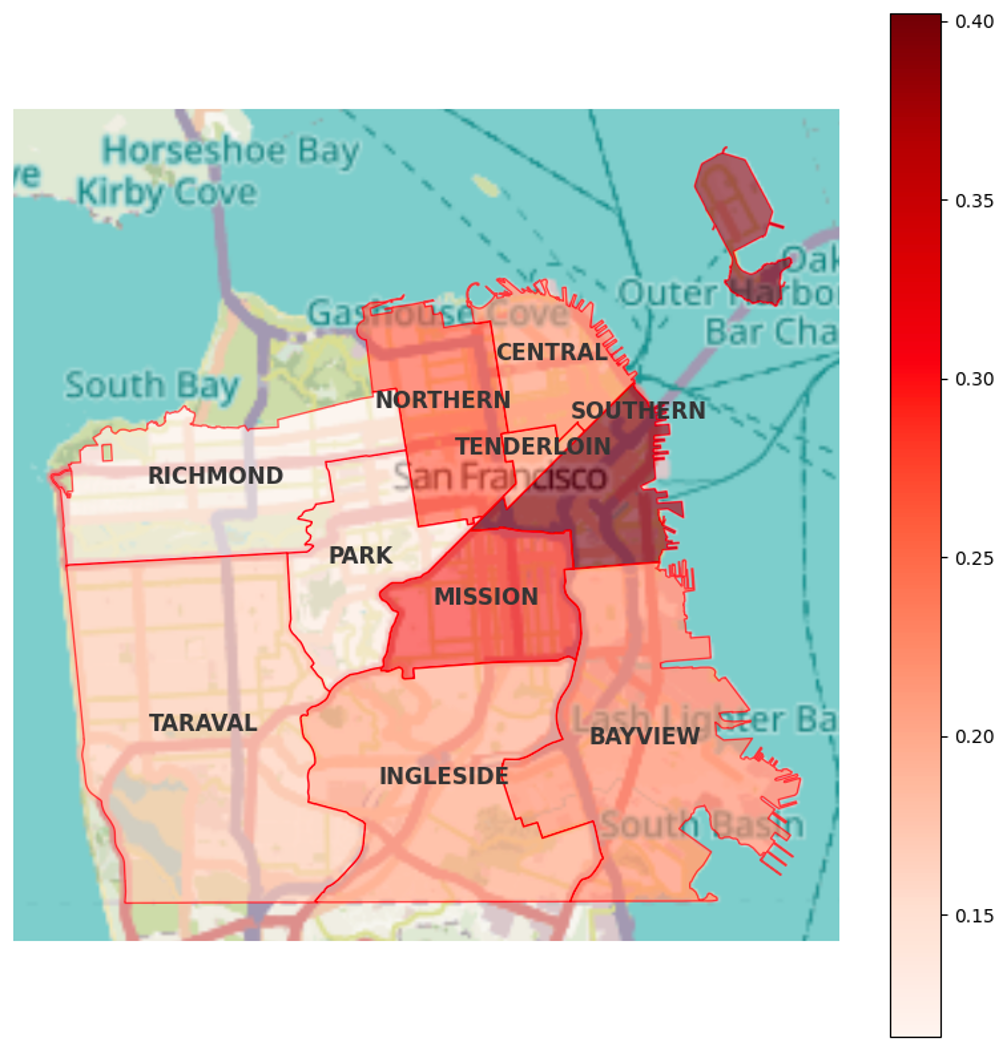
El atributo de distrito presenta variaciones notorias. “Southern” concentra casi 160 mil incidentes de los 800 mil totales.
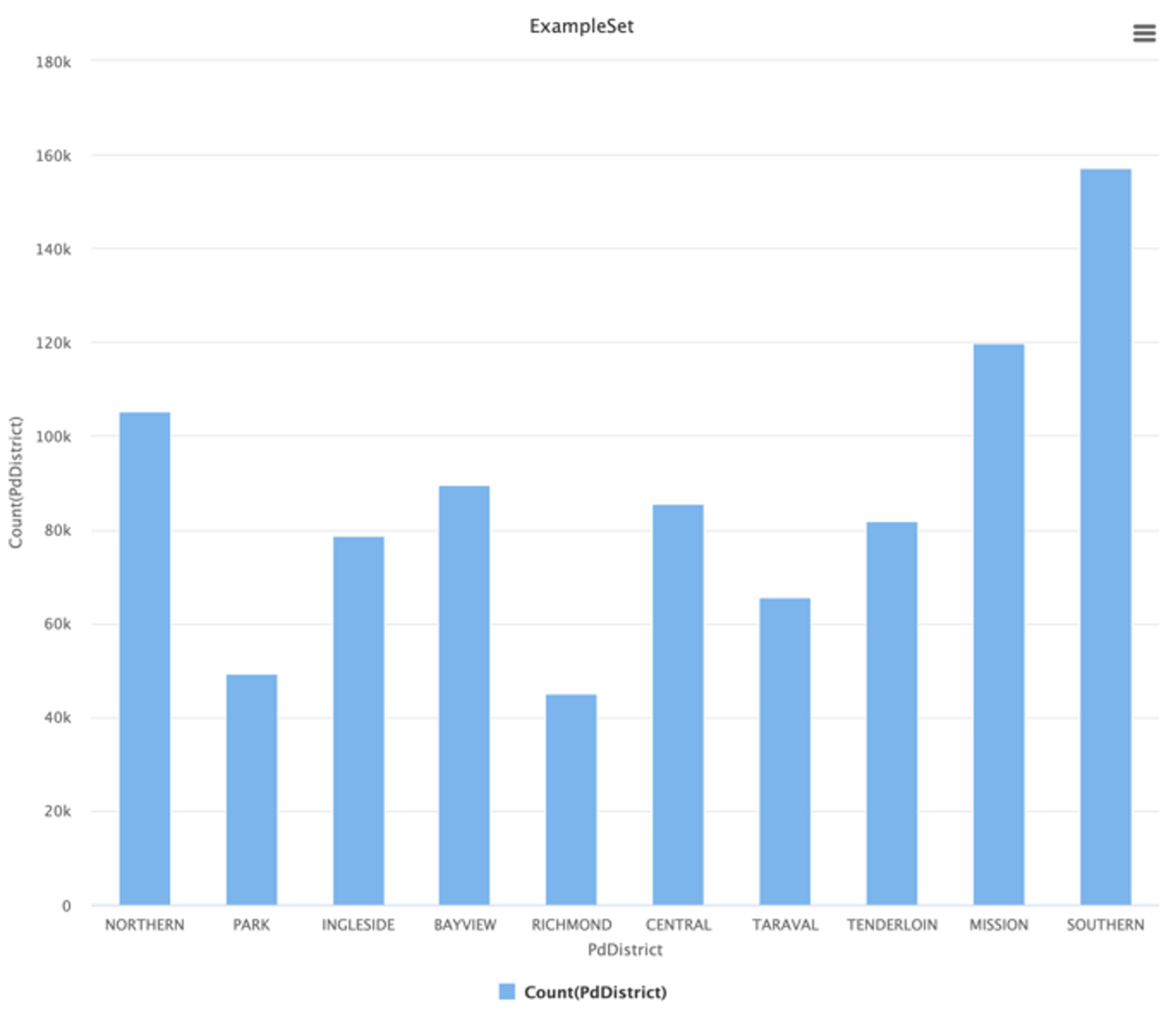
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# Descarga del shapefile del área
url = 'https://data.sfgov.org/api/geospatial/wkhw-cjsf?method=export&format=Shapefile'
with urllib.request.urlopen(url) as response, open('pd_data.zip', 'wb') as out_file:
shutil.copyfileobj(response, out_file)
with zipfile.ZipFile('pd_data.zip', 'r') as zip_ref:
zip_ref.extractall('pd_data')
for filename in os.listdir('./pd_data/'):
if re.match(".+\.shp", filename):
pd_districts = gpd.read_file('./pd_data/' + filename)
break
pd_districts.crs = {'init': 'epsg:4326'}
pd_districts = pd_districts.merge(
train.groupby('PdDistrict').count().iloc[:, [0]].rename(columns={'Dates': 'Incidents'}),
how='inner',
left_on='district',
right_index=True,
suffixes=('_x', '_y')
)
pd_districts = pd_districts.to_crs({'init': 'epsg:3857'})
# Incidentes diarios por distrito
train_days = train.groupby('Dates').count().shape[0]
pd_districts['inc_per_day'] = pd_districts.Incidents / train_days
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
# Graficar
fig, ax = plt.subplots(figsize=(10, 10))
pd_districts.plot(
column='inc_per_day',
cmap='Reds',
alpha=0.6,
edgecolor='r',
linestyle='-',
linewidth=1,
legend=True,
ax=ax
)
def add_basemap(ax, zoom, url):
"""Agrega un mapa base al gráfico"""
xmin, xmax, ymin, ymax = ax.axis()
basemap, extent = ctx.bounds2img(xmin, ymin, xmax, ymax, zoom=zoom)
ax.imshow(basemap, extent=extent, interpolation='bilinear')
ax.axis((xmin, xmax, ymin, ymax))
add_basemap(ax, zoom=11, url='http://tile.stamen.com/terrain/tileZ/tileX/tileY.png')
for index in pd_districts.index:
plt.annotate(
pd_districts.loc[index].district,
(
pd_districts.loc[index].geometry.centroid.x,
pd_districts.loc[index].geometry.centroid.y
),
color='#353535',
fontsize='large',
fontweight='heavy',
horizontalalignment='center'
)
ax.set_axis_off()
plt.show()
La visualización evidencia que el noroeste de la ciudad concentra gran parte de los delitos. Llama la atención que “Park”, ubicado en el centro, registre solo 45.209 incidentes, notablemente menos que sus vecinos.
Descript
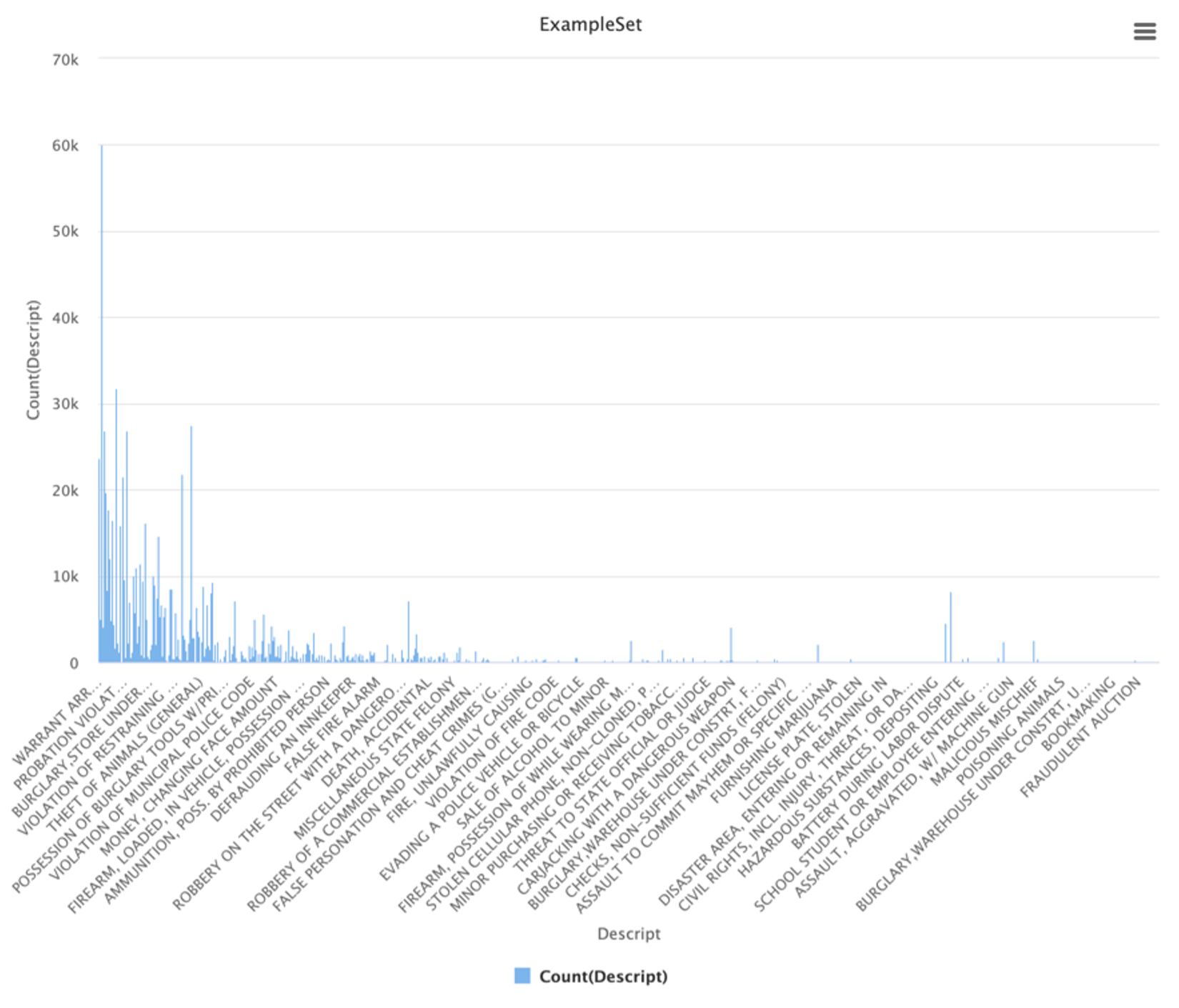
El campo Descript presenta 879 valores únicos y aporta información redundante con Category, por lo que no resulta útil para entrenar el modelo. No tiene sentido intentar predecir la categoría a partir de la descripción textual de esa misma categoría.
DayOfWeek
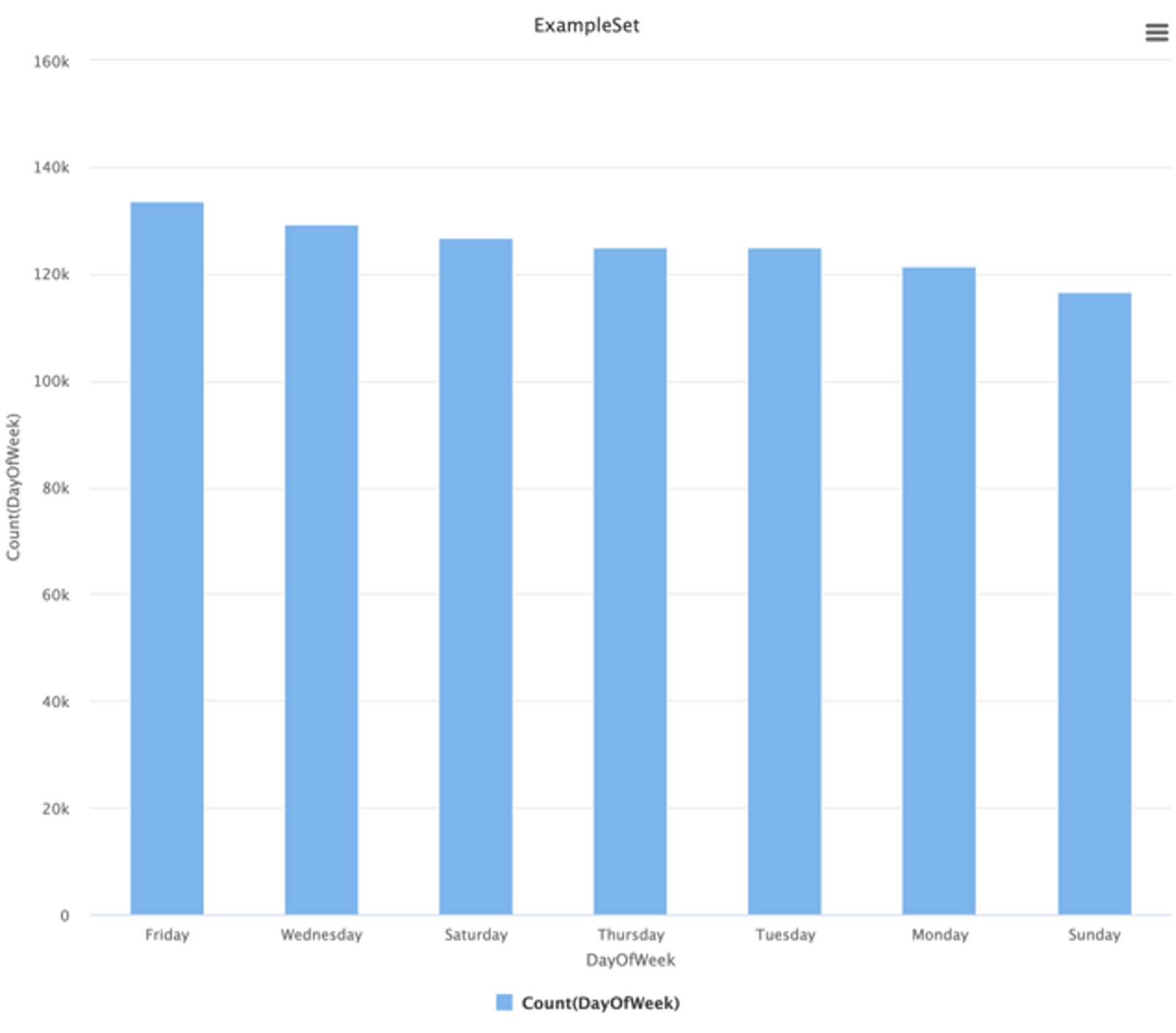
La distribución semanal es casi uniforme: no se observan picos importantes los fines de semana. Por tanto, es un candidato a descartarse o a codificarse de forma simple.
Resolution
Resolution tampoco aporta valor predictivo; para conocer la resolución es necesario saber primero qué tipo de delito ocurrió.
Address
Address contiene 23.228 direcciones únicas. Por sí sola es difícil de utilizar en un modelo, pero al analizar las direcciones más frecuentes surge información relevante:
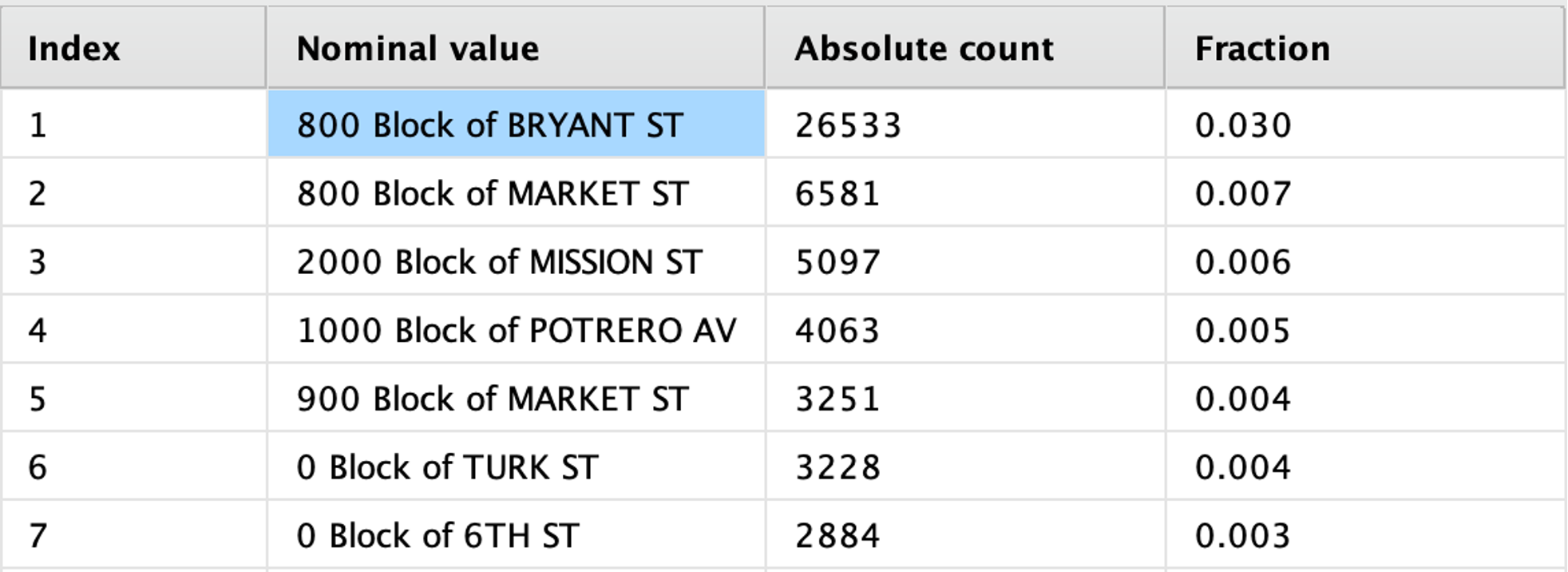
Algunos bloques (en el distrito Southern) concentran casi el 6% de todos los delitos de la ciudad. Este indicador se transforma en una nueva característica booleana (Block).
X e Y
Las coordenadas permiten trabajar el componente geográfico de manera precisa. Contamos con cuatro atributos relacionados con la ubicación:
PdDistrict: solo 10 valores que agrupan grandes zonas. Útil para visualización, no tanto para el modelo.Address: string de difícil manejo.XyY: latitud y longitud, ideales para capturar patrones espaciales.
Outliers
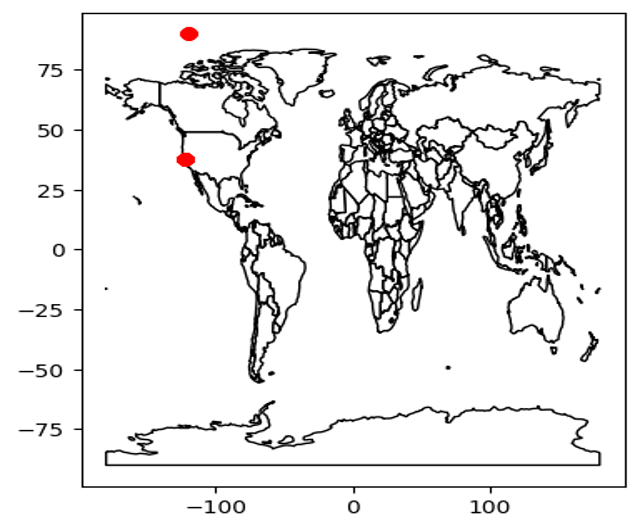
Los únicos outliers aparecen en X e Y, con puntos completamente fuera del continente. Se eliminan antes de entrenar.
1
2
3
4
5
6
7
8
9
10
11
12
13
def create_gdf(df):
gdf = df.copy()
gdf['Coordinates'] = list(zip(gdf.X, gdf.Y))
gdf.Coordinates = gdf.Coordinates.apply(Point)
gdf = gpd.GeoDataFrame(gdf, geometry='Coordinates', crs={'init': 'epsg:4326'})
return gdf
train_gdf = create_gdf(train)
world = gpd.read_file(gpd.datasets.get_path('naturalearth_lowres'))
ax = world.plot(color='white', edgecolor='black')
train_gdf.plot(ax=ax, color='red')
plt.show()
Datos duplicados
1
train.duplicated().sum()
1
2
3
4
5
6
7
8
9
10
11
train.drop_duplicates(inplace=True)
train.replace({'X': -120.5, 'Y': 90.0}, np.NaN, inplace=True)
test.replace({'X': -120.5, 'Y': 90.0}, np.NaN, inplace=True)
imp = SimpleImputer(strategy='mean')
for district in train['PdDistrict'].unique():
train.loc[train['PdDistrict'] == district, ['X', 'Y']] = imp.fit_transform(
train.loc[train['PdDistrict'] == district, ['X', 'Y']])
test.loc[test['PdDistrict'] == district, ['X', 'Y']] = imp.transform(
test.loc[test['PdDistrict'] == district, ['X', 'Y']])
Selección de atributos
A partir del análisis previo:
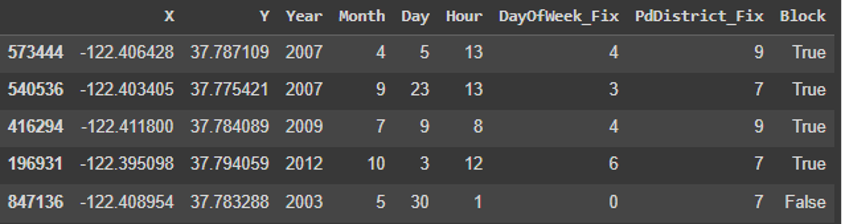
Datesse descompone enYear,Month,DayyHourpara reflejar temporalidad.Descriptse descarta por redundante.DayOfWeekse codifica a enteros (lunes=0, …).PdDistrictse elimina para evitar ruido espacial.Resolutionqueda fuera del modelo.Addressse transforma en la nueva columna booleanaBlock.XeYse conservan.
1
2
3
4
5
dates = pd.to_datetime(train["Dates"])
train["Year"] = dates.dt.year
train["Month"] = dates.dt.month
train["Day"] = dates.dt.day
train["Hour"] = dates.dt.hour
1
2
3
4
5
6
7
le = LabelEncoder()
train["Category_Fix"] = le.fit_transform(train["Category"])
train["DayOfWeek_Fix"] = le.fit_transform(train["DayOfWeek"])
train["PdDistrict_Fix"] = le.fit_transform(train["PdDistrict"])
train['Block'] = train['Address'].str.contains('block', case=False)
train_data = train.drop(columns=["Category", "DayOfWeek", "PdDistrict", "Dates", "Address", "Resolution", "Descript"])
Modelado
Entreno dos enfoques:
- Random Forest: robusto ante desbalance y capaz de manejar grandes volúmenes de datos.
- K-Nearest Neighbors: sensible a la distribución espacial, interesante para comparar.
Resultados
Random Forest
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
from sklearn.model_selection import train_test_split
X_strat, _, y_strat, _ = train_test_split(
train_data.drop("Category_Fix", axis=1),
train_data["Category_Fix"],
stratify=train_data["Category_Fix"],
test_size=0.05,
random_state=1
)
X_train, X_test, y_train, y_test = train_test_split(
X_strat,
y_strat,
test_size=0.5,
random_state=1
)
Los mejores parámetros encontrados: 60 árboles, profundidad máxima 32 y random_state=1.
1
2
3
4
5
6
7
from sklearn.ensemble import RandomForestClassifier
random_forest_model = RandomForestClassifier(
n_estimators=60,
max_depth=32,
random_state=1
)
- Accuracy (train): 0.91399
- Log loss (train): 0.444
- Accuracy (test): 0.5865
- Log loss (test): 5.8776
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
from sklearn.preprocessing import label_binarize
y_test_bin = label_binarize(y_test, classes=np.unique(y_test))
random_forest_model.fit(X_train, y_train)
y_scores = random_forest_model.predict_proba(X_test)
n_classes = len(np.unique(y_test))
fpr, tpr, roc_auc = {}, {}, {}
for i in range(n_classes):
fpr[i], tpr[i], _ = roc_curve(y_test_bin[:, i], y_scores[:, i])
roc_auc[i] = roc_auc_score(y_test_bin[:, i], y_scores[:, i])
plt.figure(figsize=(20, 16))
for i in range(n_classes):
plt.plot(fpr[i], tpr[i], label=f'Clase {i} (AUC = {roc_auc[i]:.2f})')
plt.plot([0, 1], [0, 1], 'k--')
plt.xlabel('Tasa de falsos positivos')
plt.ylabel('Tasa de verdaderos positivos')
plt.title('Curva ROC por clase')
plt.legend(loc='best')
plt.show()
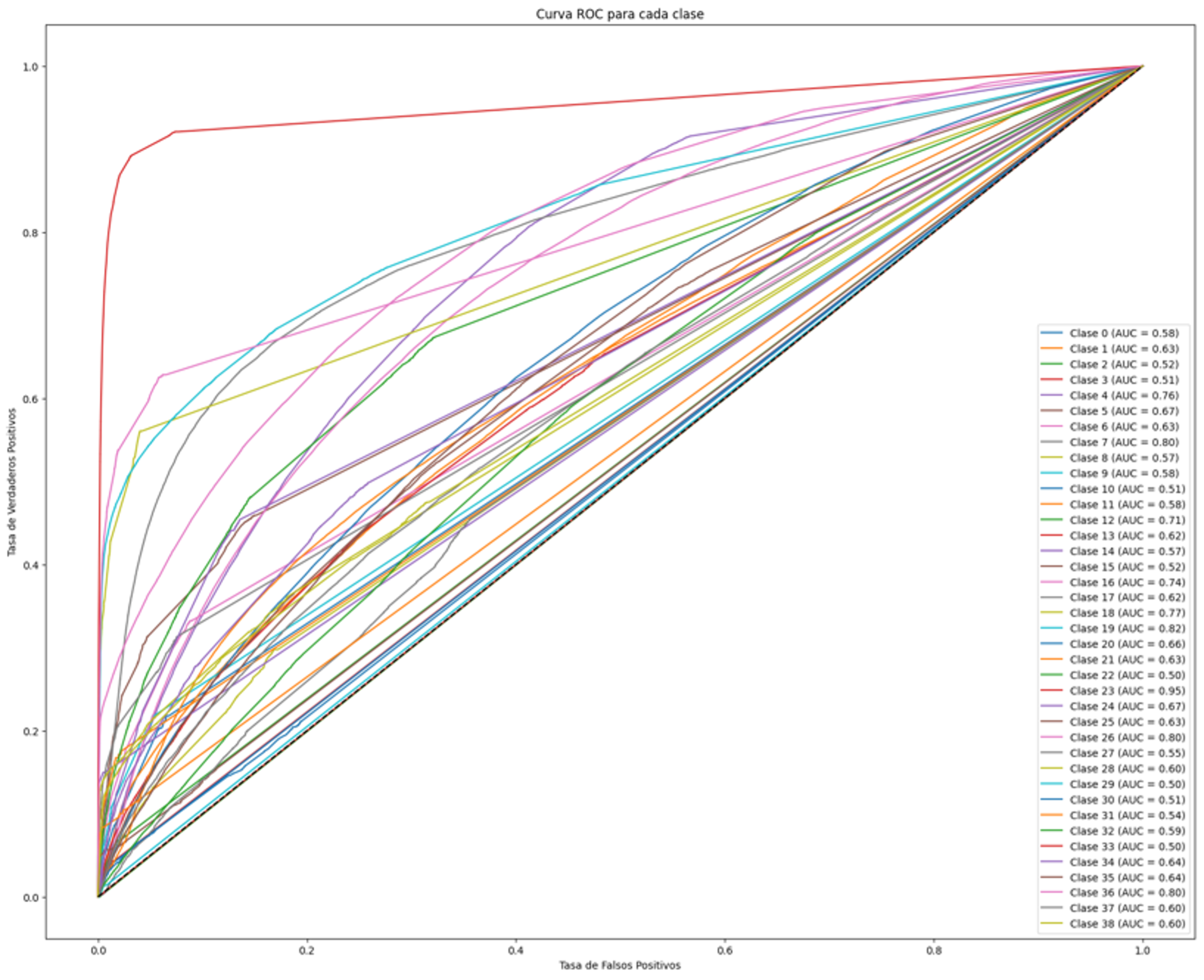
El modelo destaca por mejorar la detección de “Larceny”, principal categoría, y mantener bajas tasas de falsos negativos en el resto.
KNN
1
2
knn_model.fit(X_train, y_train)
print(model_result(knn_model))
- Accuracy (train): 0.3415
- Log loss (train): 1.627
- Accuracy (test): 0.1889
- Log loss (test): 15.114
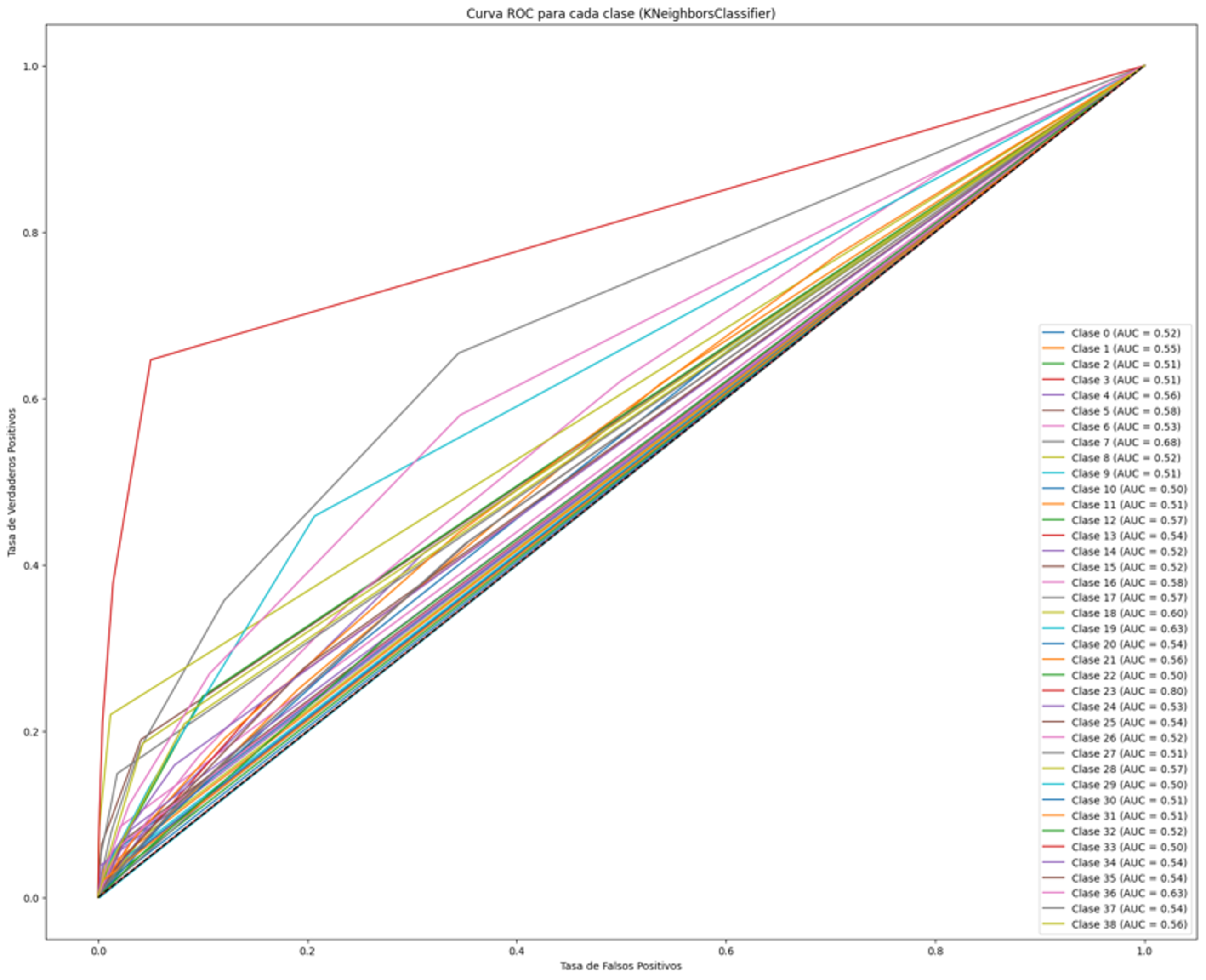
KNN se inclina casi por completo a predecir “Larceny”, generando muchos falsos positivos en las demás clases. Por eso la accuracy general es engañosa.
Conclusión
Los modelos implementados en Python rinden mucho mejor que sus equivalentes en RapidMiner. Random Forest alcanza cerca del 92% de accuracy en entrenamiento y ofrece la mejor capacidad de clasificación, mientras que KNN confirma la importancia de considerar la estructura espacial. En este dataset, Random Forest es la alternativa más equilibrada entre precisión y robustez.