Stellar Classification - SDSS17

Stellar Classification - SDSS17
De chico siempre me fascinó el espacio. La inmensidad del universo, los misterios de las galaxias y la belleza del cielo nocturno alimentaron mi curiosidad. En astronomía, una de las tareas fundamentales es clasificar objetos celestes, y el “Stellar Classification Dataset - SDSS17” ofrece la oportunidad de explorar las características espectrales de estrellas, galaxias y cuásares. Basado en observaciones del Sloan Digital Sky Survey, este dataset aporta la información necesaria para diferenciarlos. Vamos a recorrerlo.
Dataset y metadatos
Contexto

El Sloan Digital Sky Survey (SDSS) es un hito en astronomía. Se trata de un programa de imagen multiespectral y espectroscopía de corrimiento al rojo operado con un telescopio óptico de 2,5 metros ubicado en Apache Point (Nuevo México). Desde el año 2000 transformó nuestra comprensión del universo.
El proyecto se apoya en instrumentación disruptiva: una cámara CCD de exploración multi-filtro/multi-array para obtener imágenes de alta calidad y un espectrógrafo multiobjeto/multifibra que capta espectros de numerosos objetos de manera simultánea.

Uno de los grandes retos fue procesar el enorme volumen de datos generado cada noche. SDSS impulsó el almacenamiento de grandes bases y su acceso remoto, algo novedoso para la época.
La cámara fotométrica cuenta con 30 CCD SITe/Tektronix de 2048×2048 píxeles dispuestos en seis columnas por cinco filas. Los filtros r, i, u, z y g cubren cada fila en ese orden. El telescopio opera en modo drift scan: la cámara lee lentamente mientras el telescopio se desplaza y mantiene a los objetos alineados con las columnas del sensor.
Contenido
El dataset incluye 100.000 observaciones caracterizadas por 17 atributos y una etiqueta (class) que identifica al objeto como estrella, galaxia o cuásar. Descripción de los campos principales:
obj_ID: identificador único de cada objeto en el catálogo del CAS.alpha: ascensión recta (J2000), posición este-oeste.delta: declinación (J2000), posición norte-sur.u,g,r,i,z: magnitudes en los filtros ultravioleta, verde, rojo, infrarrojo cercano e infrarrojo, respectivamente.run_ID: identificador de la pasada de observación.rereun_ID: versión del procesado aplicado a la imagen.cam_col: columna de la cámara responsable del registro.field_ID: identificador del campo fotométrico.spec_obj_ID: identificador espectroscópico.class: etiqueta (GALAXY, STAR, QSO).redshift: corrimiento al rojo.plate,MJD,fiberID: detalles del espectrógrafo (placa, fecha juliana modificada y fibra).
Análisis exploratorio
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
import warnings
warnings.filterwarnings("ignore")
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import recall_score
from sklearn.metrics import accuracy_score
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
from sklearn.metrics import precision_score, f1_score, accuracy_score
from yellowbrick.classifier import ConfusionMatrix
from sklearn.metrics import confusion_matrix
from sklearn.preprocessing import LabelEncoder
from sklearn.neighbors import LocalOutlierFactor
from imblearn.over_sampling import SMOTE
import plotly.express as px
from plotly.offline import init_notebook_mode
init_notebook_mode(connected=True)
import warnings
warnings.filterwarnings("ignore")
1
2
df = pd.read_csv("Skyserver.csv")
df.head()

1
df.info()
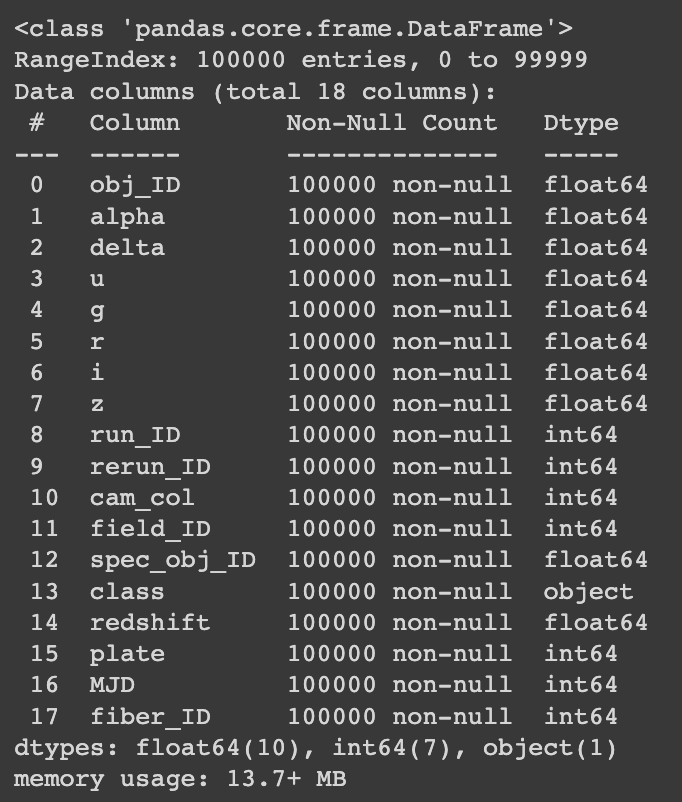
La columna class es de tipo object, por lo que la transformo a valores numéricos (GALAXY=0, STAR=1, QSO=2) para utilizarla en los modelos.
1
df["class"] = [0 if i == "GALAXY" else 1 if i == "STAR" else 2 for i in df["class"]]
No hay valores faltantes en las 100.000 filas: excelente punto de partida.
Outliers
Para detectar anomalías utilizo Local Outlier Factor (LOF), adecuado para conjuntos grandes. LOF compara la densidad local de cada punto con la de sus vecinos: si un punto está mucho más alejado que el resto, se considera un outlier.
1
2
3
4
5
6
7
8
9
10
11
12
clf = LocalOutlierFactor()
y_pred = clf.fit_predict(df)
x_score = clf.negative_outlier_factor_
outlier_score = pd.DataFrame()
outlier_score["score"] = x_score
threshold2 = -1.5
filtre2 = outlier_score["score"] < threshold2
outlier_index = outlier_score[filtre2].index.tolist()
len(outlier_index)
1
2
df.drop(outlier_index, inplace=True)
df.shape

Tras eliminar outliers quedan 84.744 filas y 18 atributos para seguir analizando.
Visualización
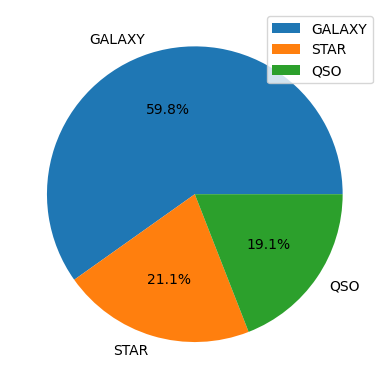
La etiqueta está desbalanceada: ~60% galaxias y 19% cuásares.
Para estudiar las características, grafico la densidad (KDE) y el histograma de cada atributo por clase y en total.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
features = df.drop('class', axis=1)
label_mapping = {0: 'Galaxy', 1: 'Star', 2: 'Quasar'}
fig, axes = plt.subplots(nrows=len(features.columns), ncols=2, figsize=(12, 2*len(features.columns)))
fig.subplots_adjust(hspace=0.5)
for i, col in enumerate(features.columns):
ax1 = axes[i, 0]
for label_value, label_name in label_mapping.items():
sns.kdeplot(data=df[df["class"] == label_value][col], label=label_name, ax=ax1)
sns.kdeplot(data=df[col], label="All", ax=ax1)
ax1.set_title(f'{col} KDE')
ax1.legend()
ax2 = axes[i, 1]
for label_value, label_name in label_mapping.items():
sns.histplot(data=df[df["class"] == label_value][col], bins=25, color='blue', alpha=0.7, ax=ax2, label=label_name)
sns.histplot(data=df[col], bins=25, color='red', alpha=0.5, ax=ax2, label="All")
ax2.set_title(f'{col} Histogram')
ax2.legend()
plt.tight_layout()
plt.show()
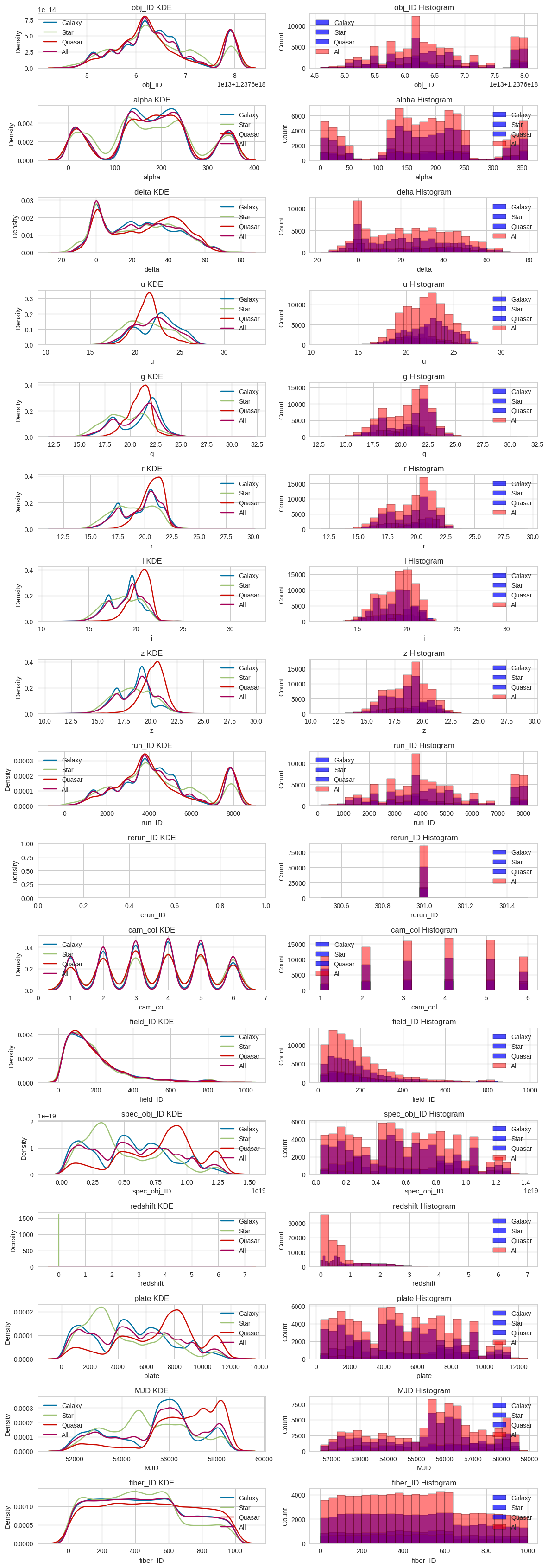
Observaciones:
obj_id,alpha,delta,run_ID,cam_colyfield_IDapenas varían con la clase: son identificadores o información poco útil para los modelos.u,g,r,i,z,platey especialmenteredshiftmuestran diferencias claras entre clases.
La matriz de correlación refuerza estas conclusiones.
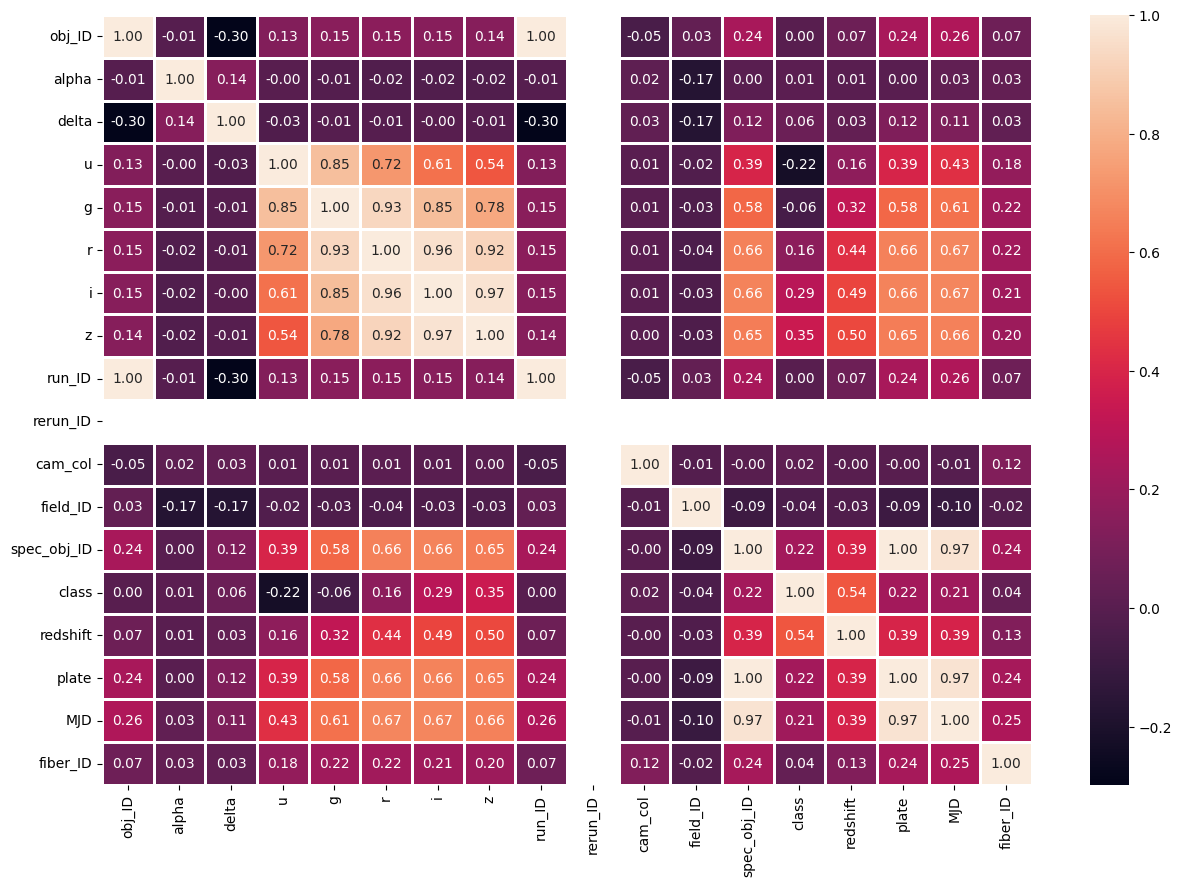
0= Galaxy ·1= Star ·2= Quasar
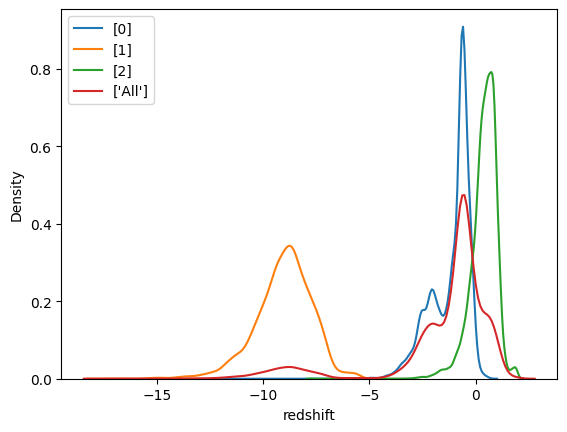
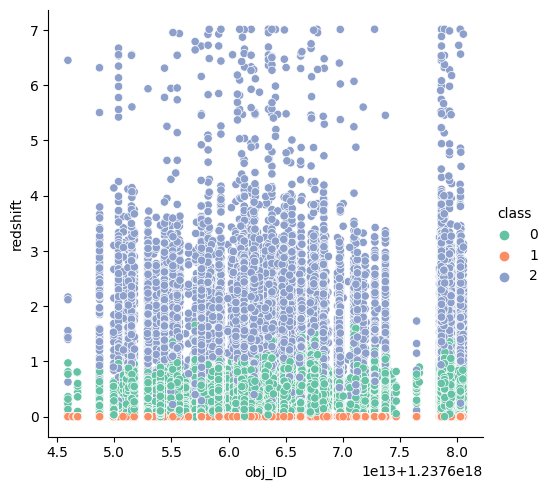
Redshift es el atributo más correlacionado con la etiqueta (~0.54). Valores entre -15 y -5 predominan en estrellas, entre -3 y -0.5 en galaxias, y mayores a 1 en cuásares. Lo mismo se aprecia en la vista de dispersión:
Con base en el análisis, conservo u, g, r, i, z, redshift y plate; descarto el resto.
Balanceo de clases
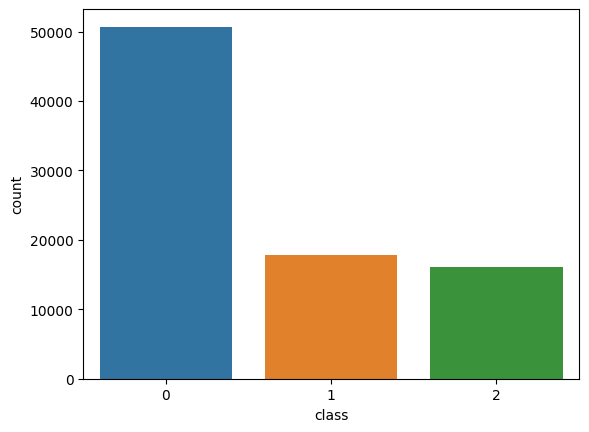
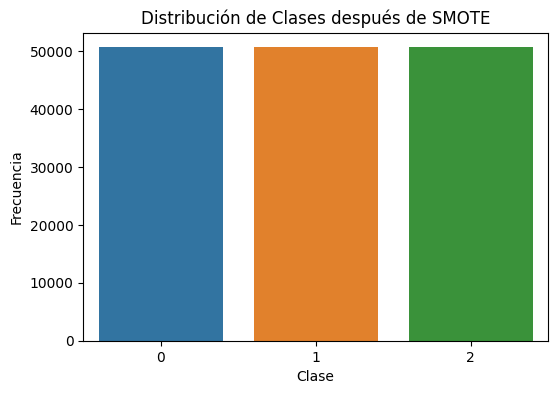
Aplico SMOTE para sobremuestrear las clases minoritarias y mantener toda la información disponible.
1
2
3
4
5
6
7
smote = SMOTE(random_state=42)
X = df.drop('class', axis=1)
y = df['class']
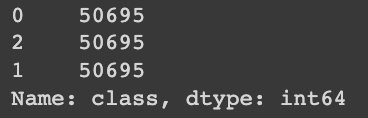
X_resampled, y_resampled = smote.fit_resample(X, y)
print(y_resampled.value_counts())
1
2
3
4
5
6
7
8
y_resampled_df = pd.DataFrame({'class': y_resampled})
plt.figure(figsize=(6, 4))
sns.countplot(x='class', data=y_resampled_df)
plt.title("Distribución de clases después de SMOTE")
plt.xlabel("Clase")
plt.ylabel("Frecuencia")
plt.show()
Trabajo finalmente con los atributos seleccionados:
1
2
X = X_resampled[['u', 'g', 'r', 'i', 'z', 'redshift', 'plate']]
X.shape
Antes de entrenar, normalizo con MinMaxScaler para escalar todo entre 0 y 1.
1
2
3
4
5
6
7
df = X.copy()
scaler = MinMaxScaler()
for i in ['u', 'g', 'r', 'i', 'z', 'redshift', 'plate']:
df[i] = scaler.fit_transform(df[[i]])
df.head()
Modelado y evaluación
Divido los datos balanceados en entrenamiento y prueba (70/30) y pruebo seis algoritmos.
1
2
classes = ['GALAXY', 'STAR', 'QSO']
X_train, X_test, y_train, y_test = train_test_split(df, y_resampled, test_size=0.3, random_state=42)
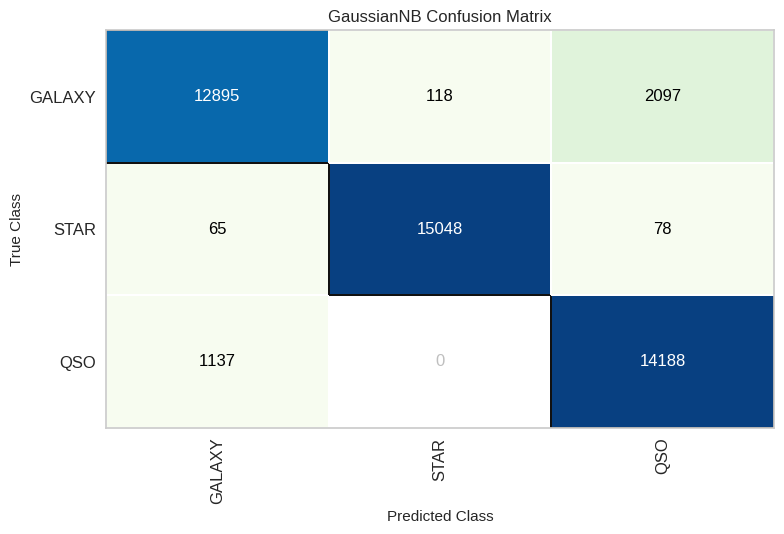
Naïve Bayes
1
2
3
4
5
6
from sklearn.naive_bayes import GaussianNB
modelNB = GaussianNB()
modelNB.fit(X_train, y_train)
y_pred4 = modelNB.predict(X_test)
gnb_score = recall_score(y_test, y_pred4, average='weighted')

1
2
3
4
NB_cm = ConfusionMatrix(modelNB, classes=classes, cmap='GnBu')
NB_cm.fit(X_train, y_train)
NB_cm.score(X_test, y_test)
NB_cm.show()
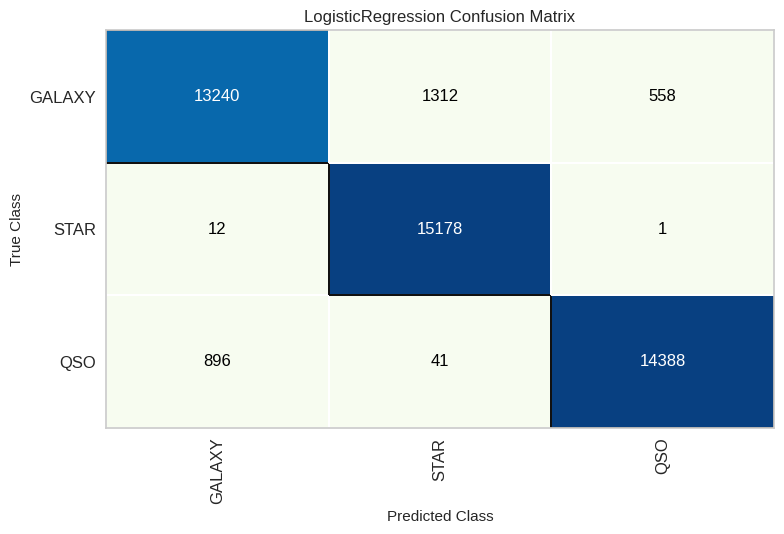
Regresión logística
1
2
3
4
modelLR = LogisticRegression(max_iter=1000)
modelLR.fit(X_train, y_train)
y_pred1 = modelLR.predict(X_test)
LR_score = recall_score(y_test, y_pred1, average='weighted')

1
2
3
4
LR_cm = ConfusionMatrix(modelLR, classes=classes, cmap='GnBu')
LR_cm.fit(X_train, y_train)
LR_cm.score(X_test, y_test)
LR_cm.show()
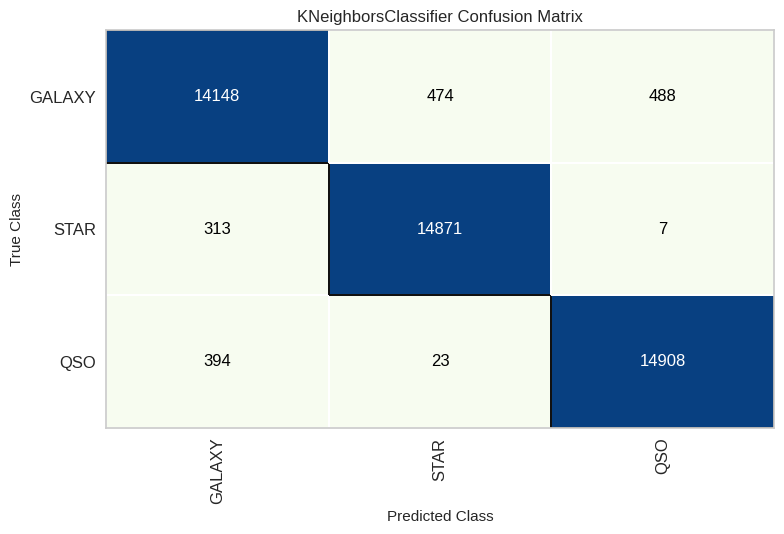
KNN
1
2
3
4
modelknn = KNeighborsClassifier(n_neighbors=1)
modelknn.fit(X_train, y_train)
y_pred2 = modelknn.predict(X_test)
knn_score = recall_score(y_test, y_pred2, average='weighted')

1
2
3
4
knn_cm = ConfusionMatrix(modelknn, classes=classes, cmap='GnBu')
knn_cm.fit(X_train, y_train)
knn_cm.score(X_test, y_test)
knn_cm.show()
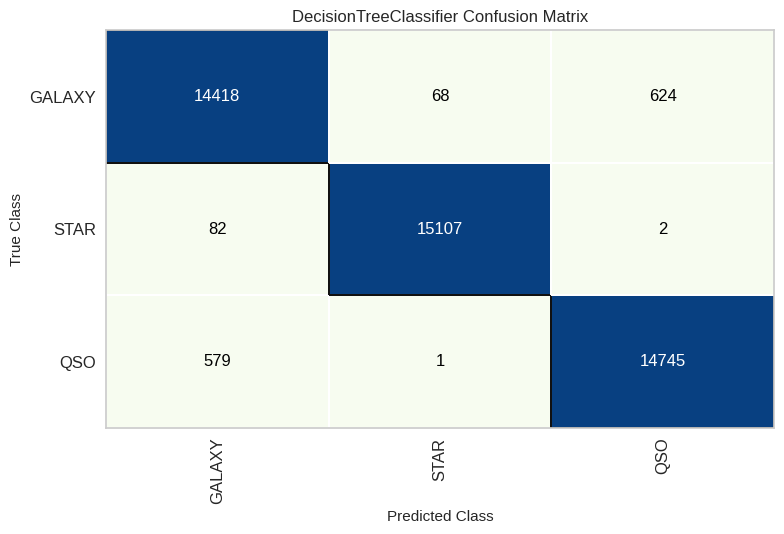
Árbol de decisión
1
2
3
4
5
from sklearn.tree import DecisionTreeClassifier
modelDT = DecisionTreeClassifier(random_state=30)
modelDT.fit(X_train, y_train)
y_pred3 = modelDT.predict(X_test)
dtree_score = recall_score(y_test, y_pred3, average='weighted')

1
2
3
4
DT_cm = ConfusionMatrix(modelDT, classes=classes, cmap='GnBu')
DT_cm.fit(X_train, y_train)
DT_cm.score(X_test, y_test)
DT_cm.show()
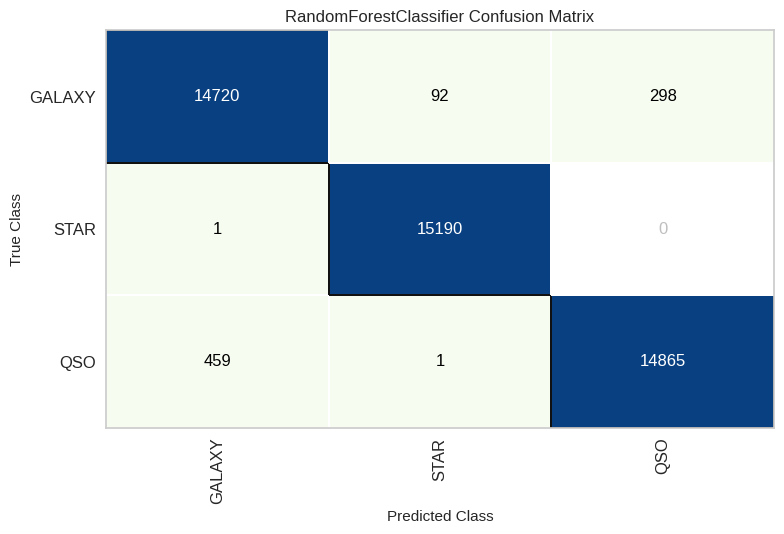
Random Forest
1
2
3
4
5
from sklearn.ensemble import RandomForestClassifier
modelRF = RandomForestClassifier(n_estimators=19, random_state=30)
modelRF.fit(X_train, y_train)
y_pred5 = modelRF.predict(X_test)
rf_score = recall_score(y_test, y_pred5, average='weighted')

1
2
3
4
RF_cm = ConfusionMatrix(modelRF, classes=classes, cmap='GnBu')
RF_cm.fit(X_train, y_train)
RF_cm.score(X_test, y_test)
RF_cm.show()
XGBoost
1
2
3
4
5
import xgboost as xgb
modelXG = xgb.XGBClassifier(random_state=42)
modelXG.fit(X_train, y_train)
y_pred6 = modelXG.predict(X_test)
xgb_score = recall_score(y_test, y_pred6, average='weighted')

1
2
3
4
XG_cm = ConfusionMatrix(modelXG, classes=classes, cmap='GnBu')
XG_cm.fit(X_train, y_train)
XG_cm.score(X_test, y_test)
XG_cm.show()
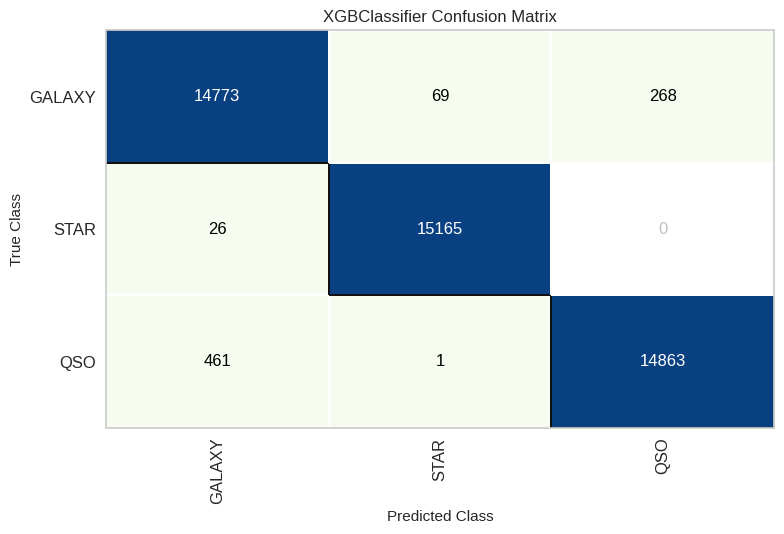
Resultados
- XGBoost y Random Forest obtienen los mejores
recallponderados. - Naïve Bayes sorprende con ~92% de accuracy pese a su simplicidad.
- La clase “Star” es la más fácil de predecir (error <0,5% en el mejor modelo), mientras que “Galaxy” presenta más confusión (~3,3% de error).
Conclusiones
Recorrimos el dataset SDSS, limpiamos outliers con LOF, seleccionamos características relevantes mediante análisis visual y correlaciones, equilibramos las clases con SMOTE y normalizamos los datos. Evaluamos seis modelos, destacándose XGBoost y Random Forest. Ese pipeline deja un punto de partida sólido para iteraciones futuras y experimentos orientados a producción.