Titanic - Machine Learning from Disaster

Titanic - Machine Learning from Disaster
El clásico dataset del Titanic es ideal para experimentar con preprocesamiento y clasificación binaria. La meta es predecir si un pasajero sobrevivió en base a sus características. En este caso el foco está en preparar los datos con Python antes de modelar.
Metadatos
- Survived: etiqueta (0 = no, 1 = sí).
- PassengerId: identificador único.
- Pclass: clase de pasaje (1ª, 2ª o 3ª).
- Name: nombre del pasajero.
- Sex: sexo.
- SibSp: número de hermanos/cónyuges a bordo.
- Parch: número de padres/hijos a bordo.
- Ticket: número de ticket.
- Fare: tarifa.
- Cabin: cabina.
- Embarked: puerto de embarque (C = Cherbourg, Q = Queenstown, S = Southampton).
Carga inicial
1
2
3
4
5
6
7
8
9
10
11
import numpy as np
import pandas as pd
import seaborn as sns
from matplotlib import pyplot as plt
sns.set_style("whitegrid")
import warnings
warnings.filterwarnings("ignore")
training = pd.read_csv("train.csv")
testing = pd.read_csv("test.csv")
1
training.head()


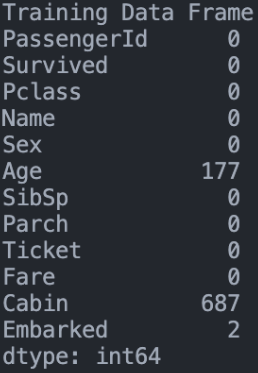
Valores faltantes
Cabintiene demasiados nulos y poca relevancia → se elimina.Ticketes solo un identificador → también se descarta.Age,EmbarkedyFarese imputan (mediana y valor más frecuente según corresponda).
1
2
3
4
5
6
7
training.drop(labels=["Cabin", "Ticket"], axis=1, inplace=True)
testing.drop(labels=["Cabin", "Ticket"], axis=1, inplace=True)
training["Age"].fillna(training["Age"].median(), inplace=True)
testing["Age"].fillna(testing["Age"].median(), inplace=True)
training["Embarked"].fillna("S", inplace=True)
testing["Fare"].fillna(testing["Fare"].median(), inplace=True)
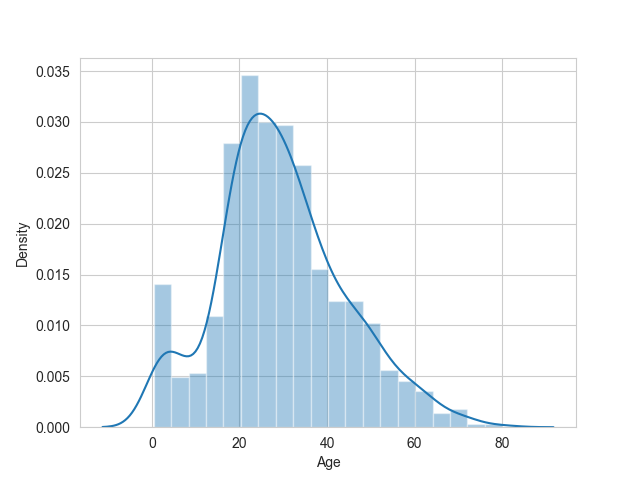
La mediana es preferible a la media porque la distribución de edades está sesgada hacia valores altos.
Visualización
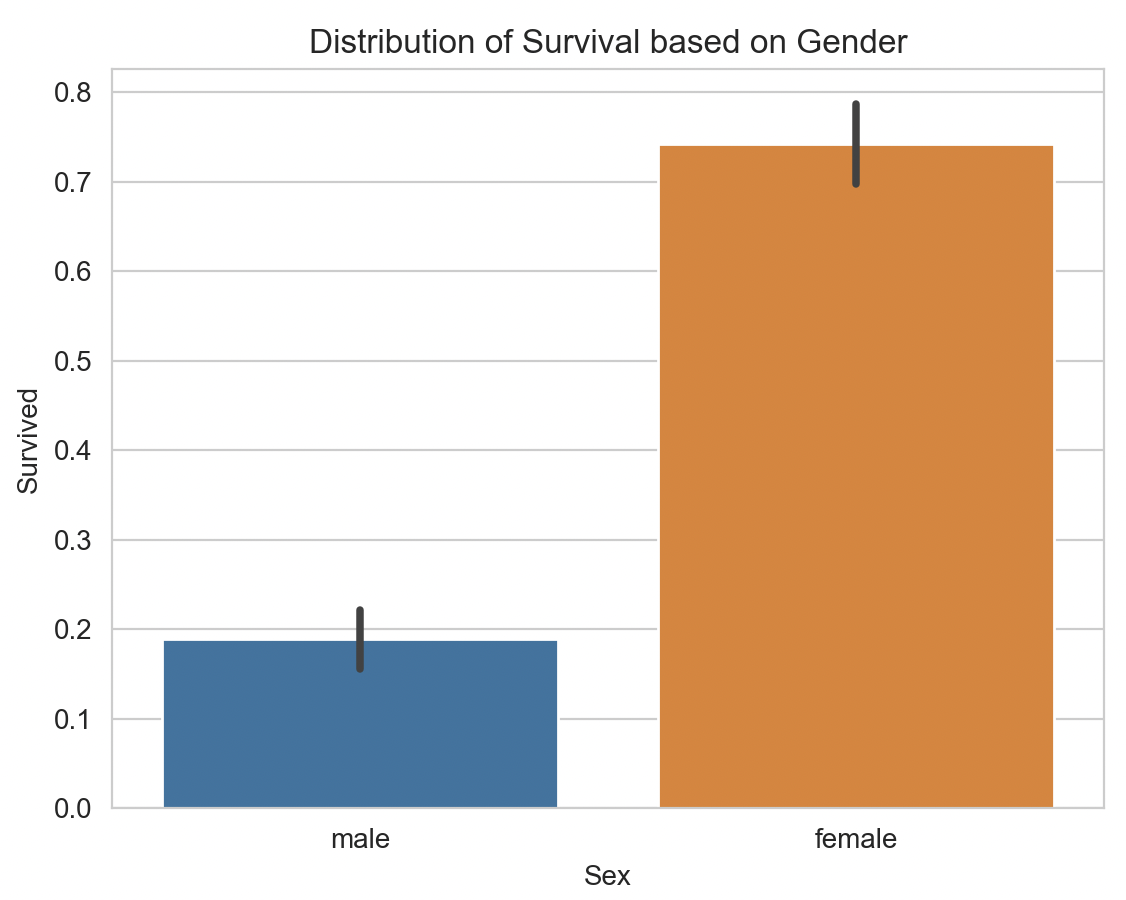
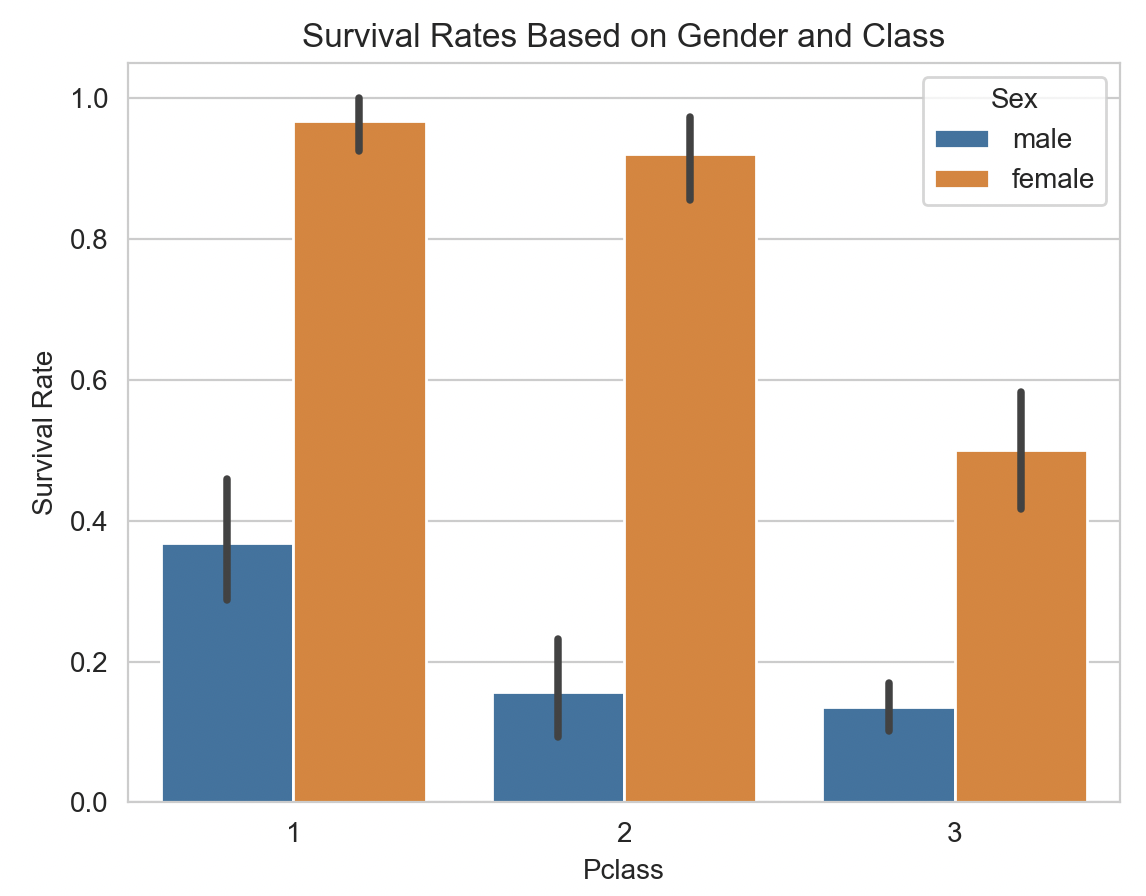
El sexo fue decisivo: las mujeres tuvieron una probabilidad de supervivencia mucho mayor.
1
2
3
4
sns.barplot(x="Pclass", y="Survived", data=training)
plt.ylabel("Survival Rate")
plt.title("Distribución de supervivencia por clase")
plt.show()
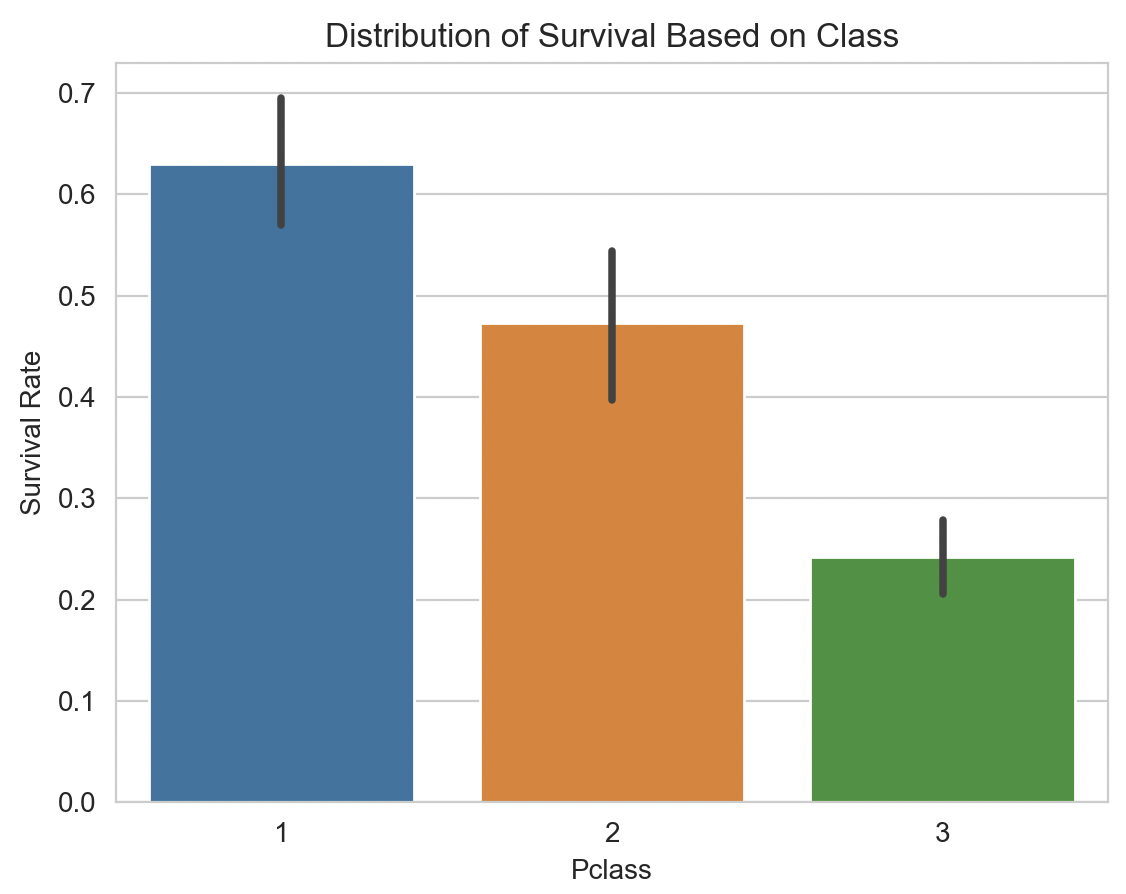
La clase también influye: en primera clase sobrevivió más del 60% de los pasajeros.
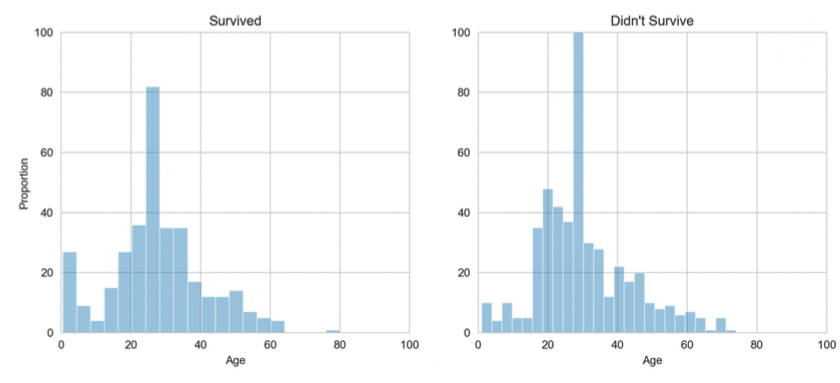
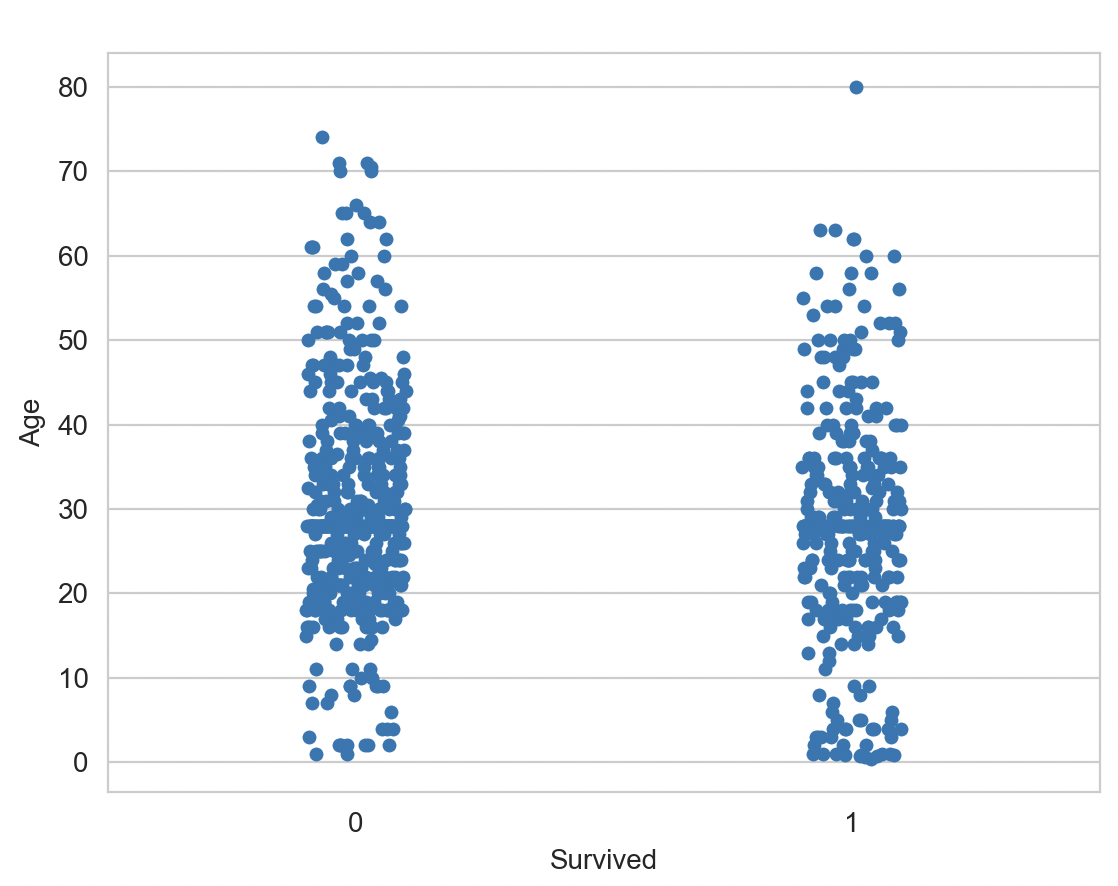
Las edades bajas tienen más chances de supervivencia; conviene conservar el atributo.
Ingeniería de variables
- Codifico
Sex: female = 1, male = 0. - Codifico
Embarked: S=1, C=2, Q=3. - Combino
SibSp+Parch→FamilySizey creoIsAlone(1 si viaja solo). - Extraigo el título del
Namey lo convierto a numérico, luego elimino la columna original.



Normalización
Age y Fare se escalan para evitar que sus magnitudes dominen.

Preparación para modelar
Se define la variable objetivo Survived y se separan PassengerId y las features. Se utiliza validación cruzada para comparar modelos y evitar sobreajuste.

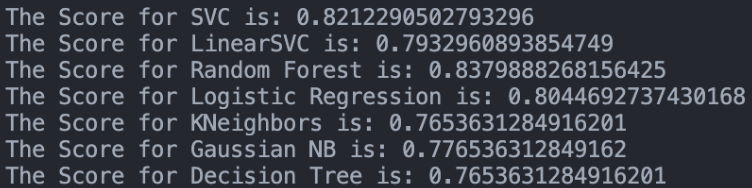

XGBoost obtiene la mejor puntuación, seguido de Random Forest y SVC. El modelo elegido genera un CSV final (418 filas) con PassengerId y la predicción Survived.