Wine - Predicting Class

Wine - Predicting Class
Este dataset de vinos fue donado en 1991 para evaluar herramientas de inteligencia artificial. El objetivo es determinar el origen de los vinos mediante análisis químicos. Contiene 178 muestras y 13 atributos con los resultados del análisis de vinos cultivados en la misma región de Italia pero provenientes de tres cultivares distintos. Originalmente había unas 30 variables, aunque solo la versión de 13 columnas está disponible.
Metadatos
- Alcohol: contenido alcohólico.
- Malic Acid: cantidad de ácido málico.
- Ash: contenido de cenizas.
- Alcalinity of Ash: alcalinidad de las cenizas.
- Magnesium: contenido de magnesio.
- Total Phenols: fenoles totales.
- Flavanoids: concentración de flavonoides.
- Nonflavanoid Phenols: fenoles no flavonoides.
- Proanthocyanins: concentración de proantocianidinas.
- Color Intensity: intensidad de color.
- Hue: matiz del vino.
- OD280/OD315 of Diluted Wines: densidad óptica del vino diluido.
- Proline: concentración del aminoácido prolina.
Carga y exploración inicial
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
df = pd.read_csv("wine.csv")
X = df.drop('Class', axis=1)
y = df['Class']
df.head()

1
df.describe()
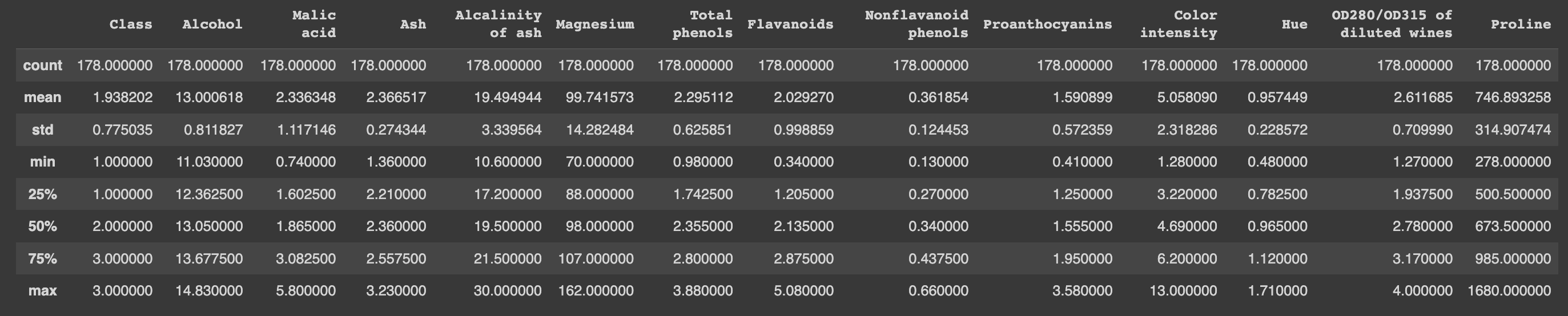
1
df.info()
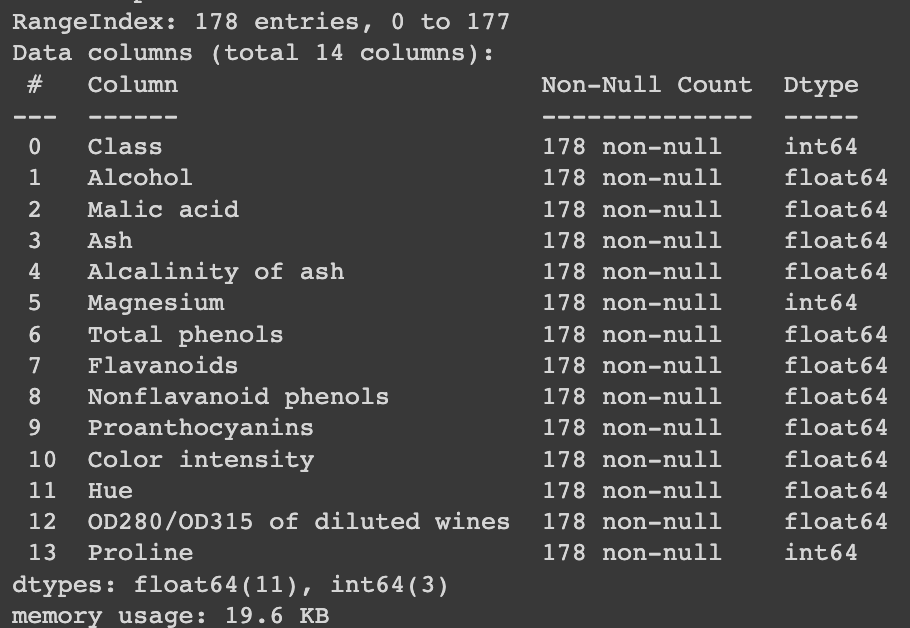
Conclusiones preliminares:
- No hay valores faltantes.
- Las escalas de los atributos son muy distintas (p. ej.
MagnesiumvsHue), lo que requiere normalización.
Analizo la distribución de cada característica:
1
2
3
4
5
6
7
8
9
10
11
features = df.drop('Class', axis=1)
fig, axes = plt.subplots(nrows=4, ncols=4, figsize=(12, 10))
fig.subplots_adjust(hspace=0.5)
for i, col in enumerate(features.columns):
ax = axes[i // 4, i % 4]
features[col].hist(bins=25, color='blue', alpha=0.7, ax=ax)
ax.set_title(col)
plt.show()
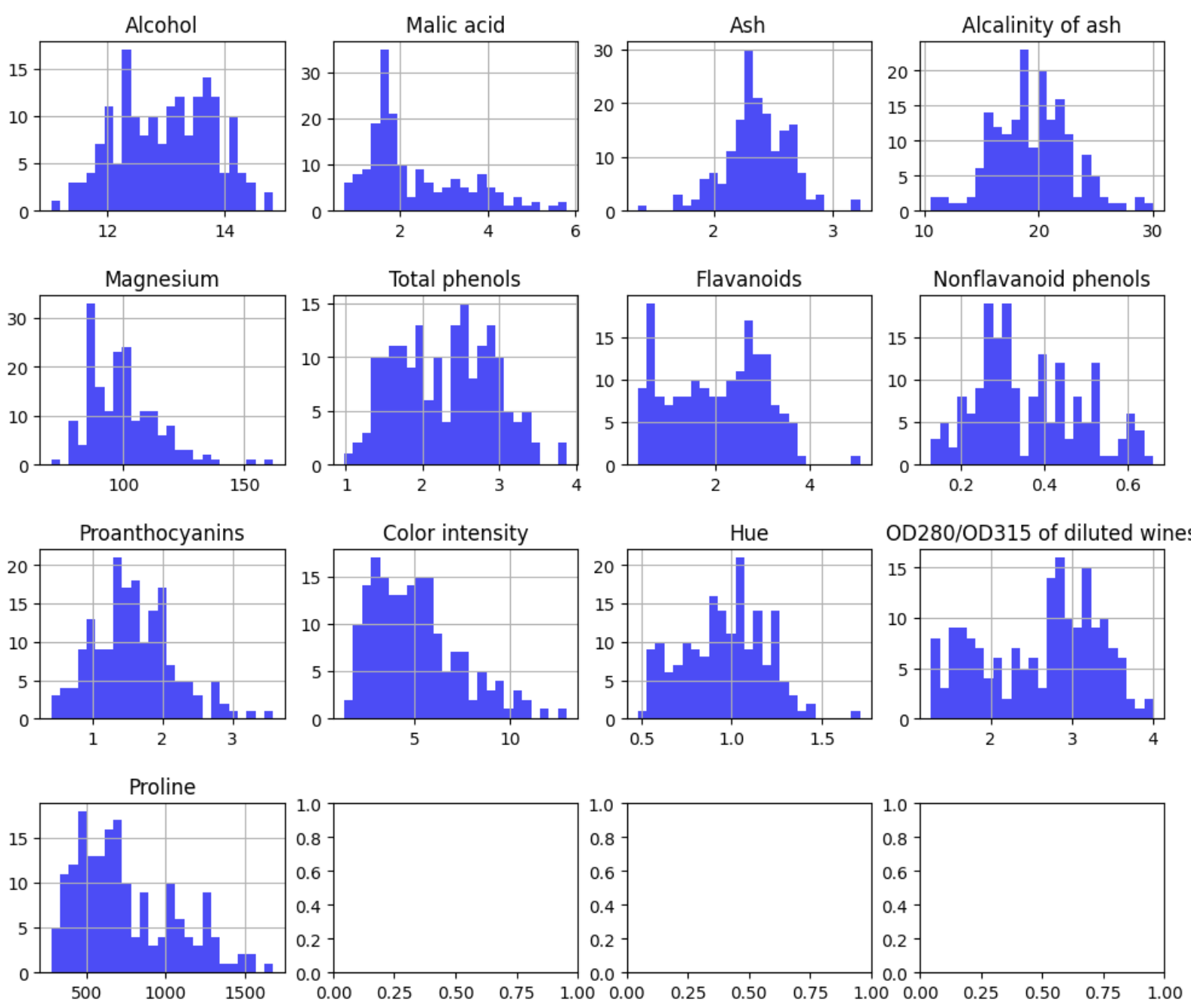
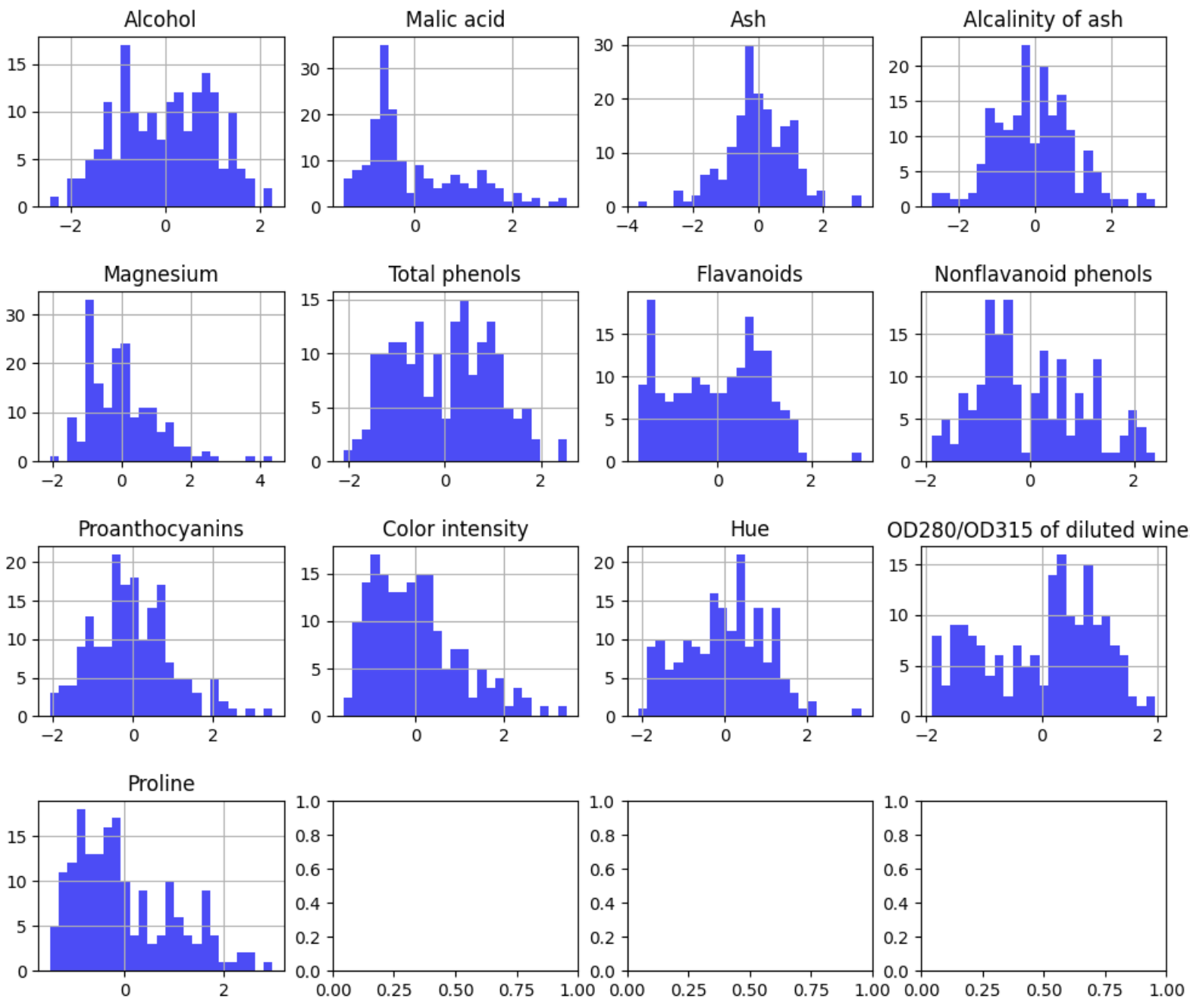
La mayoría de las variables siguen una distribución aproximadamente normal. Aplico estandarización (z-score):
1
2
3
scaler = StandardScaler()
X_normalized = scaler.fit_transform(features)
X_normalized_df = pd.DataFrame(X_normalized, columns=features.columns)
Outliers
Uso boxplots y un umbral de 2.7 desviaciones estándar para detectar outliers (dataset pequeño, no conviene eliminar demasiados puntos).
1
2
3
4
5
6
7
fig, ax = plt.subplots(ncols=5, nrows=3, figsize=(20, 10))
ax = ax.flatten()
for index, col in enumerate(X_normalized_df.columns):
sns.boxplot(y=col, data=X_normalized_df, color='b', ax=ax[index])
plt.tight_layout(pad=0.5, w_pad=0.7, h_pad=5.0)
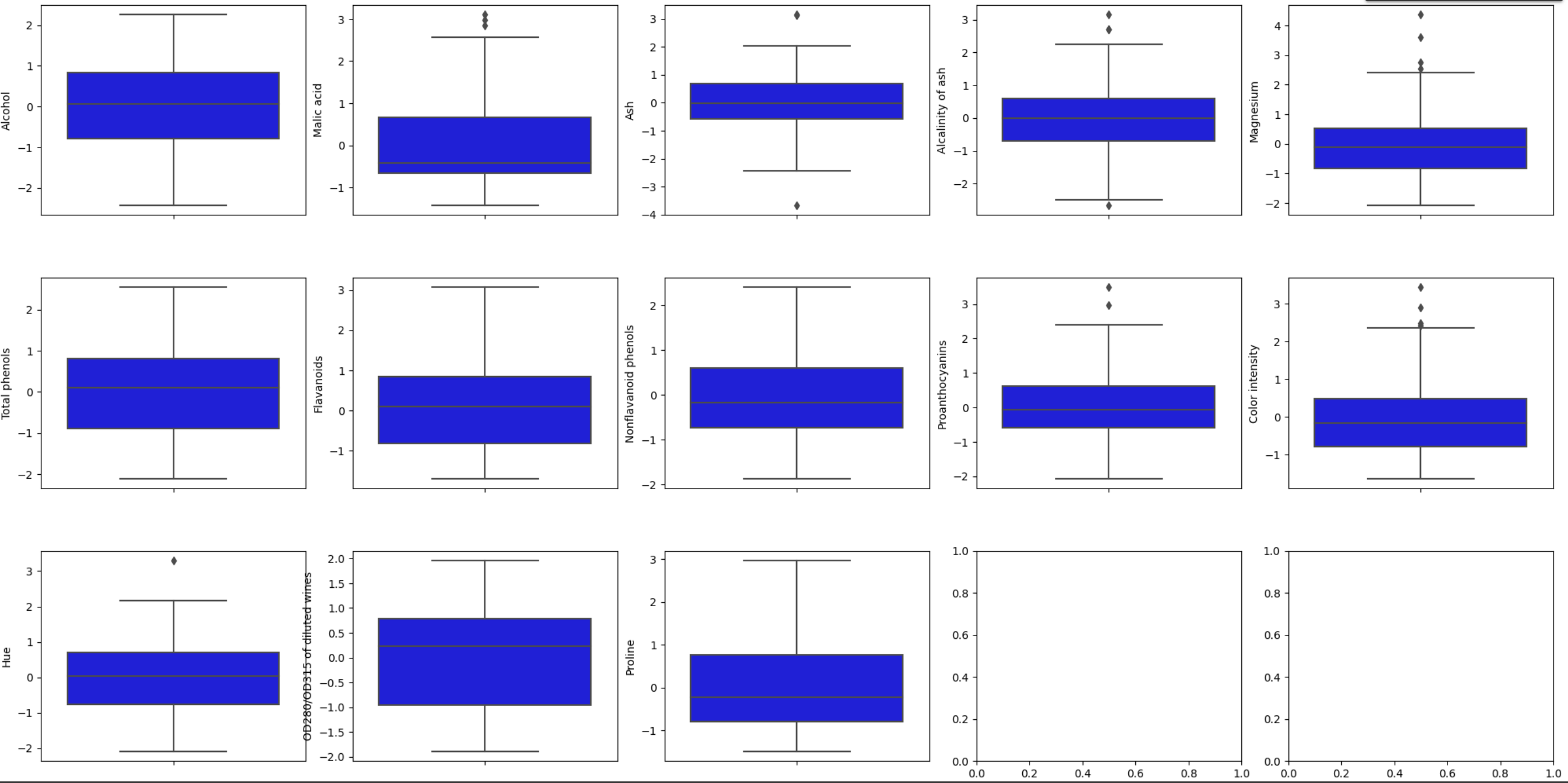
1
2
3
4
5
6
7
8
9
10
11
12
13
def detect_outliers(column, threshold=2.7):
mean = np.mean(column)
std_deviation = np.std(column)
outliers = (column - mean).abs() > threshold * std_deviation
return outliers
columns_with_outliers = []
for column in X_normalized_df.columns:
outliers = detect_outliers(X_normalized_df[column])
if outliers.any():
columns_with_outliers.append(column)
print(f"Column '{column}' has {outliers.sum()} outliers.")

1
2
# Dataset normalizado y sin outliers
sns.pairplot(df_sin_outliers)
Correlación
1
2
plt.figure(figsize=(15, 10))
sns.heatmap(df.corr(), annot=True, fmt='.2f', linewidths=2)
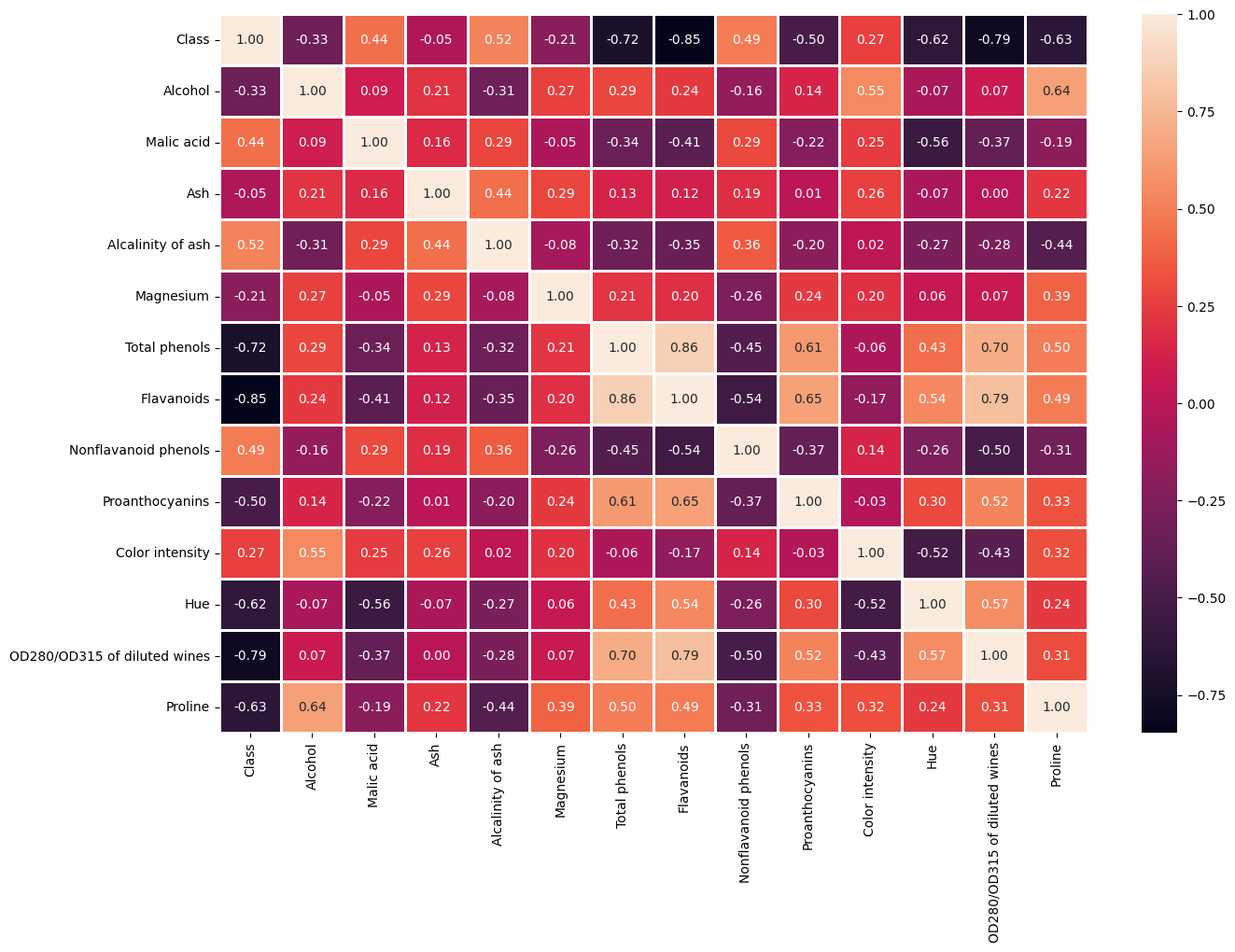
Hallazgos:
Ashtiene correlación prácticamente nula con la etiqueta, por lo que puede descartarse.Total phenols,FlavanoidsyOD280/OD315exhiben alta correlación con la clase (>0.70) pero también entre sí. Intenté combinar variables y aplicar PCA, pero los resultados no mejoraron.- LDA (Linear Discriminant Analysis) funcionó mejor porque maximiza la separación entre clases.
Modelado
Comparo tres escenarios: sin reducción, con PCA y con LDA, para tres algoritmos.
Random Forest
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
clf = RandomForestClassifier(random_state=42)
y = y[df_sin_outliers.index]
scores = cross_val_score(clf, df_sin_outliers, y, cv=5)
print("Mean Accuracy (sin reducción):", scores.mean())
pca = PCA(n_components=2)
X_pca = pca.fit_transform(df_sin_outliers)
scoresPCA = cross_val_score(RandomForestClassifier(random_state=42), X_pca, y, cv=5)
print("Mean Accuracy (PCA):", scoresPCA.mean())
lda = LinearDiscriminantAnalysis(n_components=2)
X_lda = lda.fit_transform(df_sin_outliers, y)
scoresLDA = cross_val_score(RandomForestClassifier(random_state=42), X_lda, y, cv=5)
print("Mean Accuracy (LDA):", scoresLDA.mean())

SVC
1
2
3
4
5
6
7
8
9
10
11
clf_svc = SVC(random_state=42)
y = y[df_sin_outliers.index]
scores_svc = cross_val_score(clf_svc, df_sin_outliers, y, cv=5)
print("Mean Accuracy (sin reducción):", scores_svc.mean())
scores_svc_pca = cross_val_score(SVC(random_state=42), X_pca, y, cv=5)
print("Mean Accuracy (PCA):", scores_svc_pca.mean())
scores_svc_lda = cross_val_score(SVC(random_state=42), X_lda, y, cv=5)
print("Mean Accuracy (LDA):", scores_svc_lda.mean())

KNN
1
2
3
4
5
6
7
8
9
10
11
clf_knn = KNeighborsClassifier(n_neighbors=5)
y = y[df_sin_outliers.index]
scores_knn = cross_val_score(clf_knn, df_sin_outliers, y, cv=5)
print("Mean Accuracy (sin reducción):", scores_knn.mean())
scores_knn_pca = cross_val_score(KNeighborsClassifier(n_neighbors=5), X_pca, y, cv=5)
print("Mean Accuracy (PCA):", scores_knn_pca.mean())
scores_knn_lda = cross_val_score(KNeighborsClassifier(n_neighbors=5), X_lda, y, cv=5)
print("Mean Accuracy (LDA):", scores_knn_lda.mean())

Conclusiones
- La normalización y la eliminación selectiva de outliers mejoran la estabilidad.
- LDA entrega la mejor separación entre clases y potencia a SVC y KNN.
- Es importante monitorear posibles sobreajustes (especialmente cuando LDA acierta el 100%). Retrain periódico y validación cruzada son claves si se lleva a producción.