San Francisco Crime Classification

Context
San Francisco, renowned for its cultural diversity, technological innovation, and logistically high crime past. Crime data analysis not only provides historical insight, but also reveals patterns and trends that help to better understand crime dynamics in a city. In the specific case of San Francisco, a meticulously compiled dataset spans a crucial period from 2003 to 2015, revealing a detailed overview of crimes committed in this iconic city over more than a decade. This extensive record of incidents provides a unique window to explore the evolution of crime in San Francisco during a period of profound socioeconomic and cultural change. From technological expansion to housing challenges to the complexity of social dynamics, this city experienced significant transformations that undoubtedly impacted the incidence and nature of recorded crime. Looking at various articles on the situation in San Francisco, I will comment on some of the most important points. One in every sixteen people is a victim of property crime or violence, making it more dangerous than 98 percent of all U.S. cities. To put this in perspective, Compton, California, the infamous home of drug gang turf wars, and which today remains more dangerous than 90 percent of all U.S. cities, is nearly twice as safe as that San Francisco. The policing environment in San Francisco presents notable challenges that impact the effectiveness of law enforcement. One of these challenges lies in the ratio of police force to population: compared to cities such as New York, San Francisco has a significantly smaller police force per capita, a disparity that is linked to a troubling reality. Despite having a smaller police force, San Francisco faces significant crime rates. Once we understand a little more about the situation in San Francisco in the 1920s, we can look at the attributes given.
Data Fields
- Dates - date and time of the criminal incident
- Category - Category of the criminal incident (only in train.csv). This is the target variable to be predicted.
- Descript - detailed description of the criminal incident (only in train.csv)
- DayOfWeek - the day of the week
- PdDistrict - name of the Police Department District
- Resolution - how the criminal incident was resolved (only in train.csv)
- Address - the approximate address of the crime incident
- X - Longitude
- Y - Latitude
Input Data
Make the necesary imports
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
!pip install geoplot
!pip install contextily
!pip install eli5
!pip install pdpbox
!pip install --upgrade pdpbox
!pip install shap
## --
import pandas as pd
from shapely.geometry import Point
import geopandas as gpd
import matplotlib.pyplot as plt
import numpy as np
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
import seaborn as sns
from matplotlib import cm
import urllib.request
import shutil
import zipfile
import os
import re
import contextily as ctx
import geoplot as gplt
#from pdpbox import get_dataset
import lightgbm as lgb
import eli5
from eli5.sklearn import PermutationImportance
from lightgbm import LGBMClassifier
from matplotlib import pyplot as plt
from pdpbox import pdp, info_plots
import shap
Next, we divide the set into Train and Test and we print the first lines.
1
2
train = pd.read_csv('train.csv', parse_dates=['Dates'])
test = pd.read_csv('test.csv', parse_dates=['Dates'], index_col='Id')
1
train.head()

Data Visualization
Some graphics are opened in Rapidminer for visual reasons
To begin to introduce us to this dataset and its values, the first thing it is to overview the values of the tattributes and see what information we can get a priori. This case can be solved through supervised methods since we have the data for the models to learn from their respective labels, but a different approach can be made through unsupervised methods since taking into account the given data, these could be divided into clusters (for example) taking into account the place, time and district. The training dataset has about 878,049 rows of cases from 2003 to 2015, where no missing values are found. Another point to review is the data types, where there is quite a variety, but mostly nominal minus the coordinates. We will now take a closer look at the attributes in order to draw some conclusions.
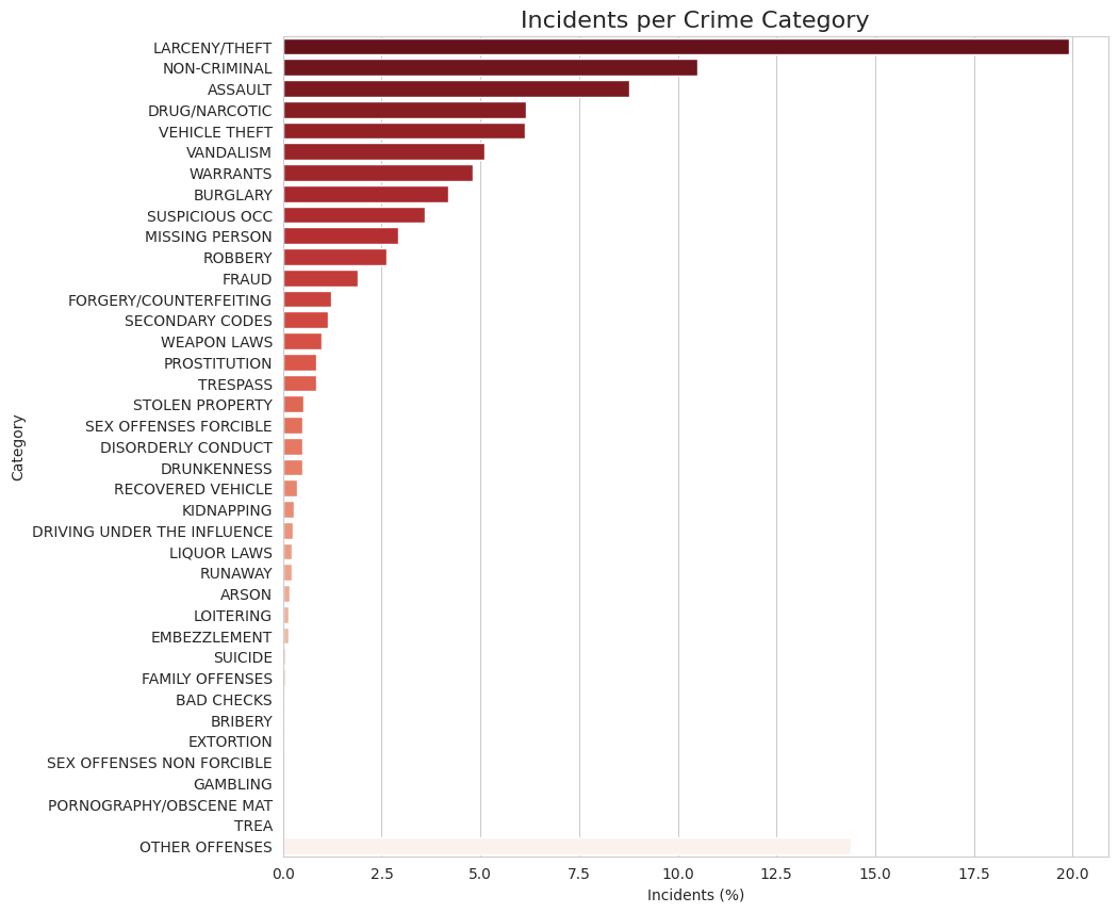
Category
Starting with “Category”, this is of nominal type and as seen in this graph it is biased, with almost 180,000 rows with category “Larceny/Theft”, while most of the categories do not exceed 8,000 rows. This may be an aspect to address more in the future when we are preparing the data to be used in models since, besides not being the most efficient, it may cause some overfitting problems in the prediction. Faced with this bias problem, there are several options to take. The first one is to leave it as it is, it is true that there would be too many values that the target variable could take, but if we would like to keep 100 percent of the categories, it could be done. Another way to take is to discretize the data, so as to group several categories that are related or belong to the same group. This can help since we would lower the number of categories that can exist and we would be abstracting a little bit from them. One of the problems we face when making this decision is that it is difficult for us to establish these groups, as they are quite distant from each other, making it difficult to group them together. Another option could be to simply choose a subset of these possible categories and train the model based on it, in this way we would be getting rid of categories that do not even reach 1000 rows and we would be staying with those that are more predominant in San Francisco.
Date
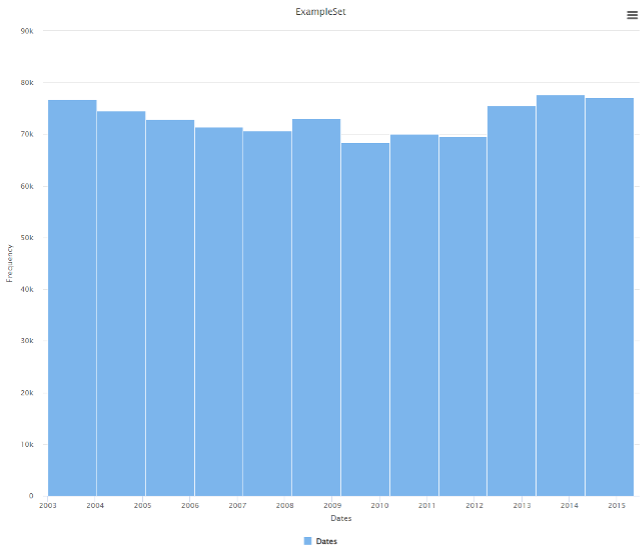
Focusing more on the dates, it is curious to see that in 12 years (2003 to 2015) the trend of robberies per year is practically the same, which reflects the lack of improvement of the city in all this time and the problems that San Francisco had in these years. Mentioning about what kind of decisions we can make based on this, first of all, this “Date” data is a DateTime type, therefore, we could have other attributes generated from this type of data (such as year, month, day and hour).s
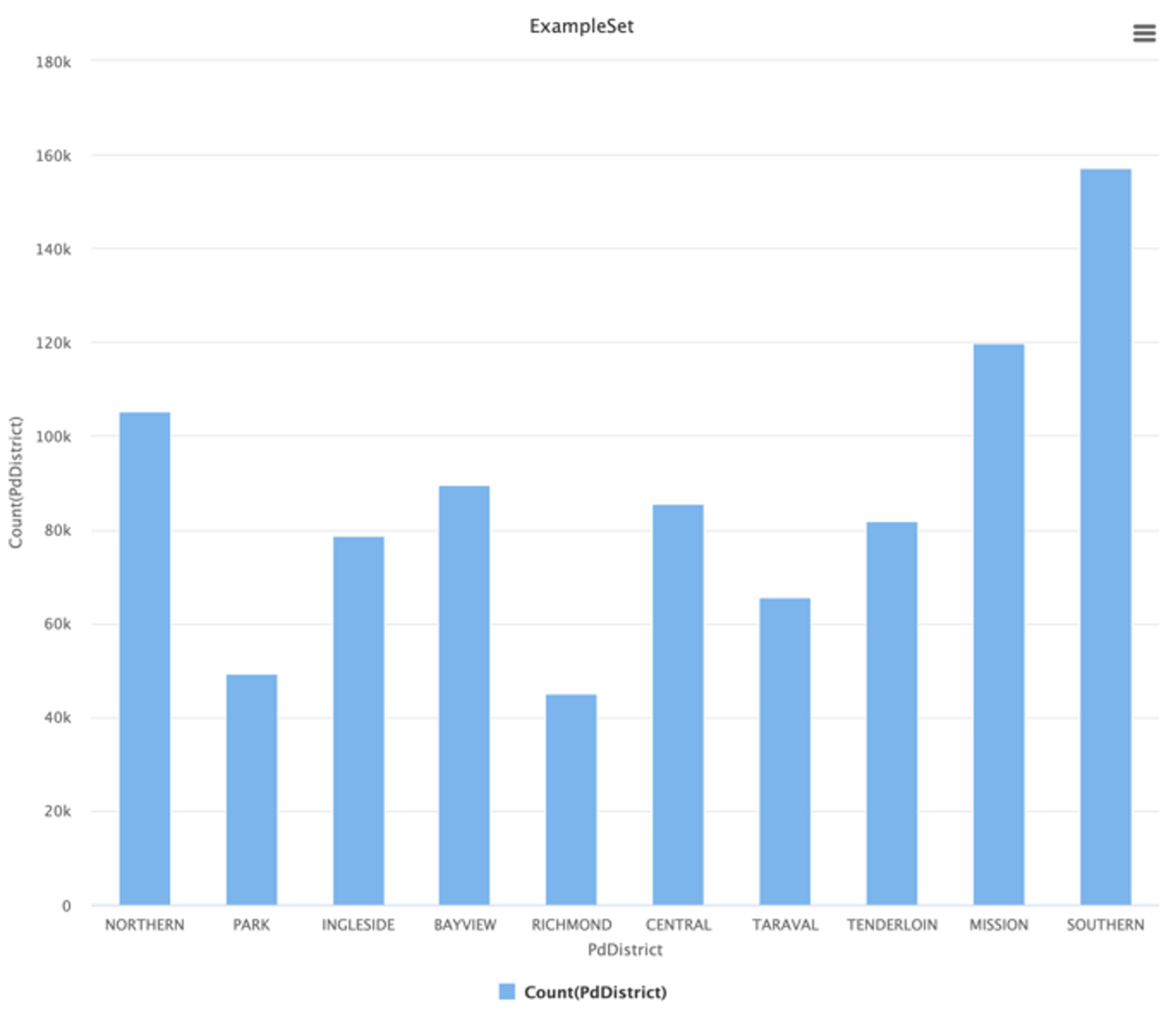
PdDistrict
In the district attribute the situation is different, since as we can see, in this case there is a significant variance among the districts. Based on this we can already speculate that this attribute may be important for the model. We can see that districts like “Southern” are extremely dangerous with almost 160 out of 800 thousand crimes.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
# Downloading the shapefile of the area
url = 'https://data.sfgov.org/api/geospatial/wkhw-cjsf?method=export&format=Shapefile'
with urllib.request.urlopen(url) as response, open('pd_data.zip', 'wb') as out_file:
shutil.copyfileobj(response, out_file)
with zipfile.ZipFile('pd_data.zip', 'r') as zip_ref:
zip_ref.extractall('pd_data')
for filename in os.listdir('./pd_data/'):
if re.match(".+\.shp", filename):
pd_districts = gpd.read_file('./pd_data/'+filename)
break
pd_districts.crs={'init': 'epsg:4326'}
pd_districts = pd_districts.merge(
train.groupby('PdDistrict').count().iloc[:, [0]].rename(
columns={'Dates': 'Incidents'}),
how='inner',
left_on='district',
right_index=True,
suffixes=('_x', '_y'))
pd_districts = pd_districts.to_crs({'init': 'epsg:3857'})
# Calculating the incidents per day for every district
train_days = train.groupby('Dates').count().shape[0]
pd_districts['inc_per_day'] = pd_districts.Incidents/train_days
# Ploting the data
fig, ax = plt.subplots(figsize=(10, 10))
pd_districts.plot(
column='inc_per_day',
cmap='Reds',
alpha=0.6,
edgecolor='r',
linestyle='-',
linewidth=1,
legend=True,
ax=ax)
def add_basemap(ax, zoom, url):
"""Función que agrega el mapa base al gráfico"""
xmin, xmax, ymin, ymax = ax.axis()
basemap, extent = ctx.bounds2img(xmin, ymin, xmax, ymax, zoom=zoom)
ax.imshow(basemap, extent=extent, interpolation='bilinear')
ax.axis((xmin, xmax, ymin, ymax))
# Adding the background
add_basemap(ax, zoom=11, url='http://tile.stamen.com/terrain/tileZ/tileX/tileY.png')
# Adding the name of the districts
for index in pd_districts.index:
plt.annotate(
pd_districts.loc[index].district,
(pd_districts.loc[index].geometry.centroid.x,
pd_districts.loc[index].geometry.centroid.y),
color='#353535',
fontsize='large',
fontweight='heavy',
horizontalalignment='center'
)
ax.set_axis_off()
plt.show()
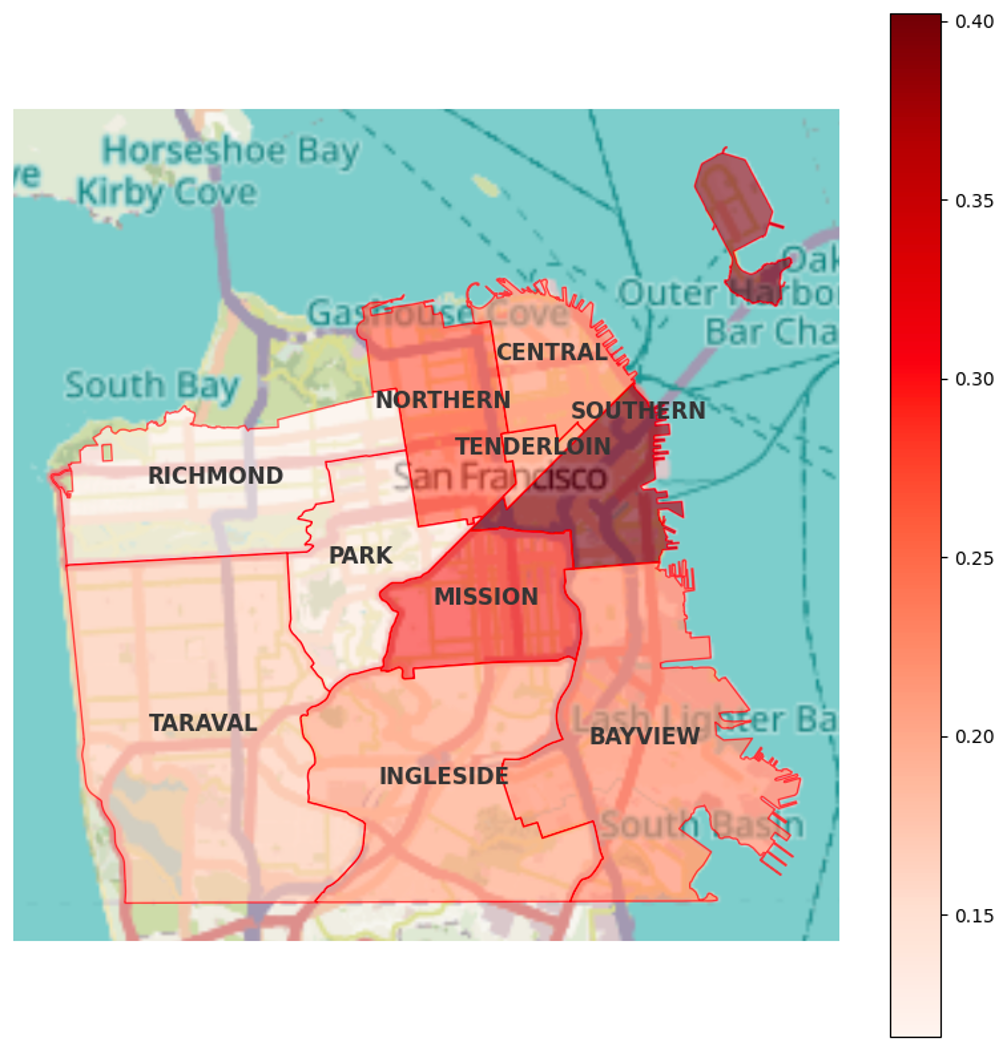
Based on this other graph, we can already notice areas where any type of crime is more likely to occur. Beyond the specific districts we can see how one area of San Francisco is the most compromised, the northwest area. And then curiously the “Park” district is the one that contains less crime compared to all the others with 45,209, even though it is in the center of the city, surrounded by districts with much higher rates.
Descript
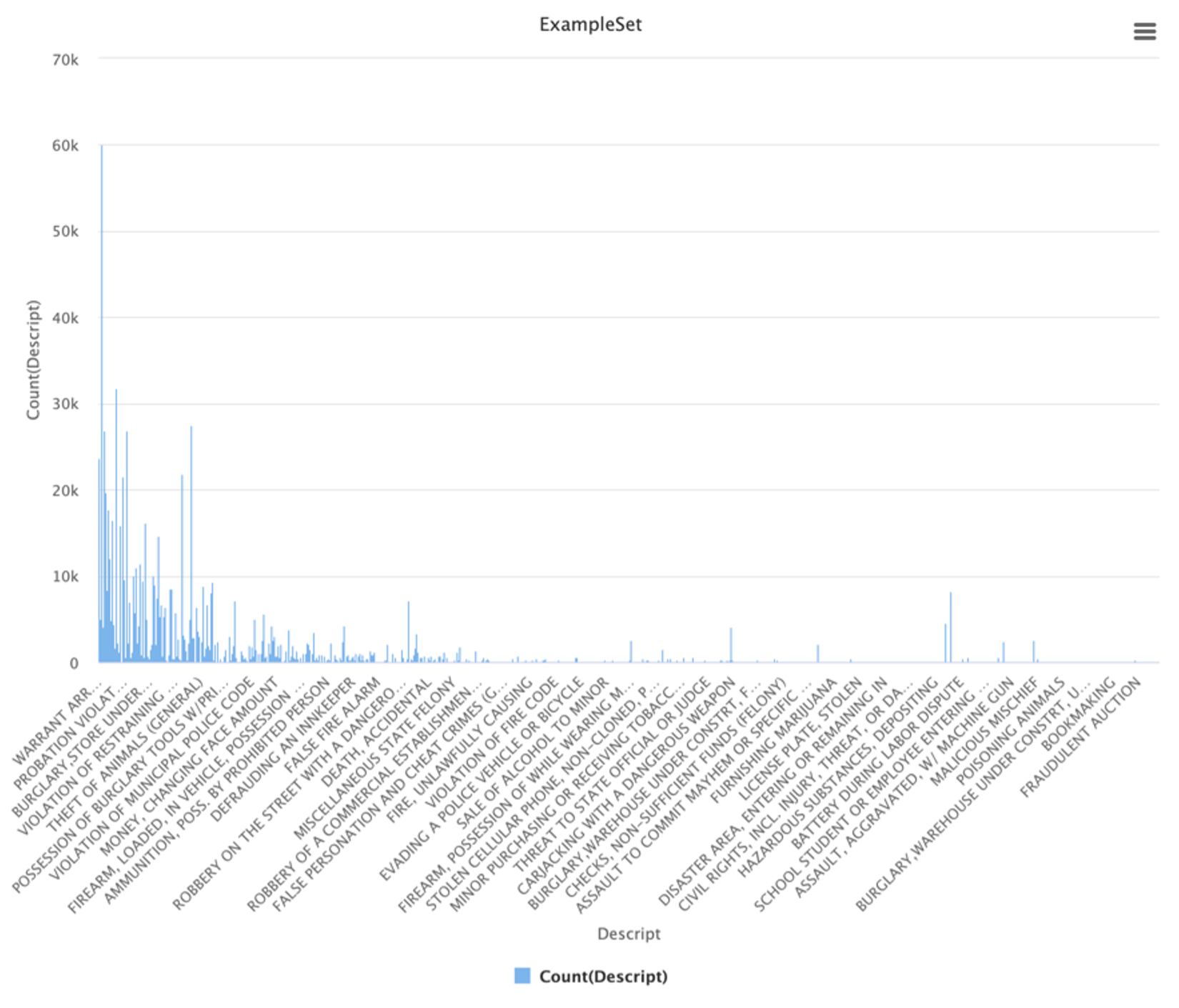
In the case of “Descript” it is similar to “Category” with the difference that it takes 879 different values. Besides the fact that right now we are not focusing on feature selection, this attribute is likely to be eliminated since it does not add much more information than what the category already adds. Considering that the target variable is “Category” it is clear that we are not going to predict category with the description of that category.
DayOfWeek
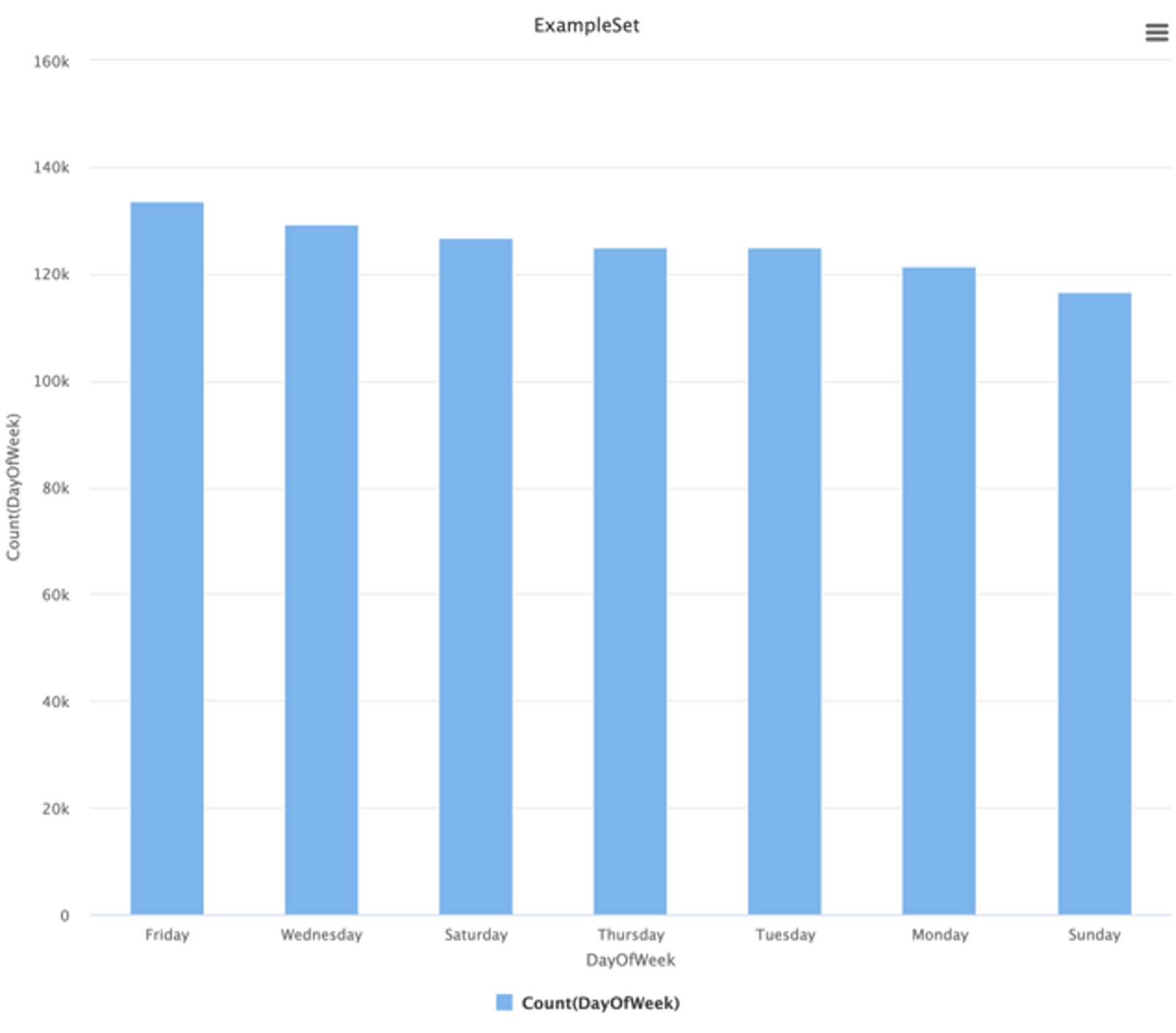
In the case of DayOfWeek, we can see that, over 12 years of crime, there is not much variation in terms of what day of the week it is, which I think is quite surprising since I expected the number of crimes to rise significantly on weekends. Thinking more about the model, this is also a candidate attribute to be eliminated as it provides almost no variation between Monday and Sunday.
Resolution
This attribute does not provide us with much information that can be useful for the model, as they are too biased and more importantly, it is not useful for predicting the category, because to know the resolution we first have to know what type of crime it is.
Address
On the other hand, we have “Address”, an attribute that does not give us much revealing information, but it is informative, this attribute has 23,228 different addresses, making it practically discarded for the model as it is a nominal data type. But if we look at the most frequented addresses, we can see this data:
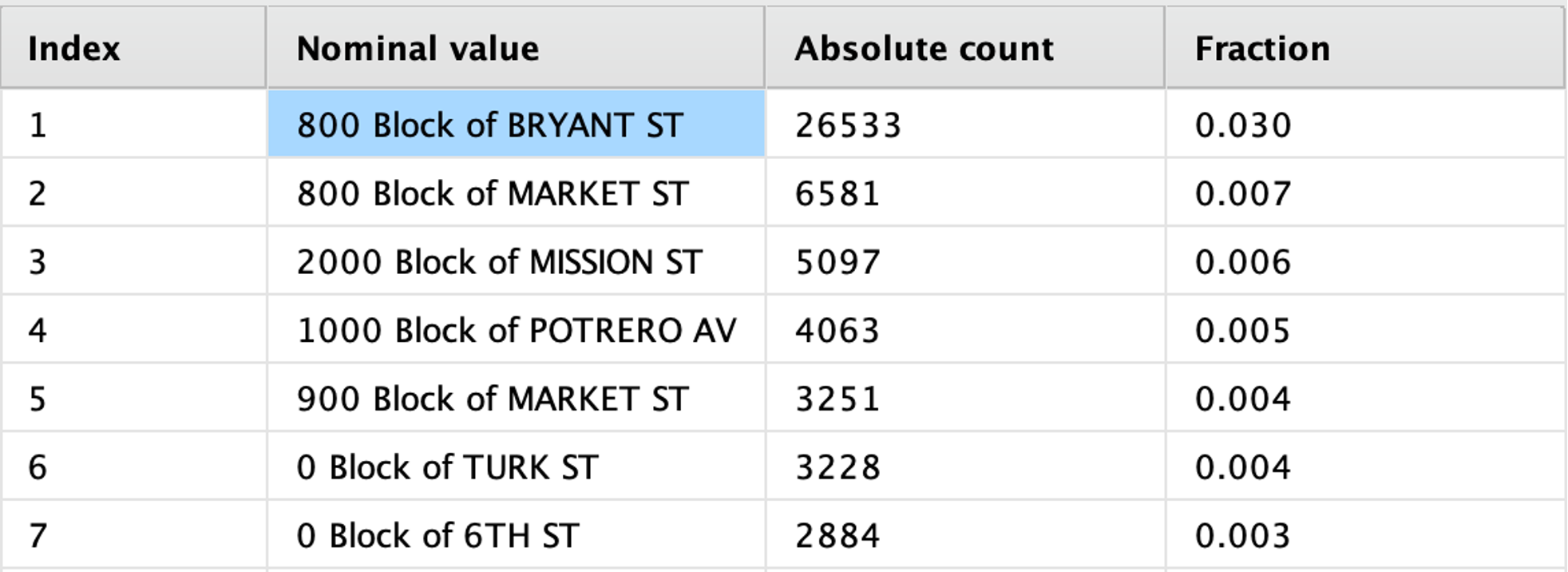
We can see that these blocks (which are located in Southern) have a large number of crimes in only one direction, representing almost 6% of the total crimes in all of San Francisco, which, when analyzed coldly, is a terrible thing, and it is something that will be taken into account when modeling.
X and Y
Finally, we have the Latitude and Longitude, a pair of attributes that changes things a lot thinking about the model. As we saw there are 4 attributes in total that describe of the same, the location of the crime:
- We have the District which divide all the total crime locations into simply 10 districts.
- It is useful for visualizing the data and categorizing the districts by dangerousness.
- Not very good for the model as, there may be cases that are in the same district, but a large number of kilometers apart, making the graph I use above unfair. Example: Perhaps only a small area of a district is where a large amount of crime occurs, making it not the best way to learn the model. It would not be the most accurate.
- On the other hand, the address simply provides a string that is very difficult for the model to handle.
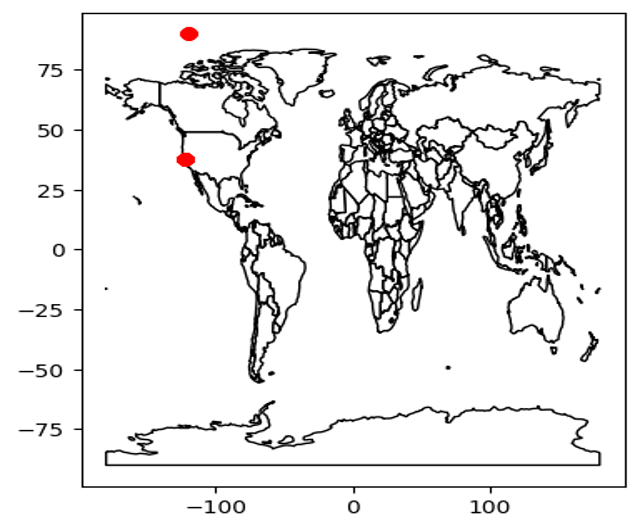
Outliers
In this dataset we only found a few outliers, in the X and Y attributes, as you can see in this graph, there are points where neither are in the same continent. Once removed the data will be ready.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
def create_gdf(df):
gdf = df.copy()
gdf['Coordinates'] = list(zip(gdf.X, gdf.Y))
gdf.Coordinates = gdf.Coordinates.apply(Point)
gdf = gpd.GeoDataFrame(
gdf, geometry='Coordinates', crs={'init': 'epsg:4326'})
return gdf
train_gdf = create_gdf(train)
world = gpd.read_file(gpd.datasets.get_path('naturalearth_lowres'))
ax = world.plot(color='white', edgecolor='black')
train_gdf.plot(ax=ax, color='red')
plt.show()
Duplicated data
1
train.duplicated().sum()
1
2
3
4
5
6
7
8
9
10
11
train.drop_duplicates(inplace=True)
train.replace({'X': -120.5, 'Y': 90.0}, np.NaN, inplace=True)
test.replace({'X': -120.5, 'Y': 90.0}, np.NaN, inplace=True)
imp = SimpleImputer(strategy='mean')
for district in train['PdDistrict'].unique():
train.loc[train['PdDistrict'] == district, ['X', 'Y']] = imp.fit_transform(
train.loc[train['PdDistrict'] == district, ['X', 'Y']])
test.loc[test['PdDistrict'] == district, ['X', 'Y']] = imp.transform(
test.loc[test['PdDistrict'] == district, ['X', 'Y']])
Feature Selection
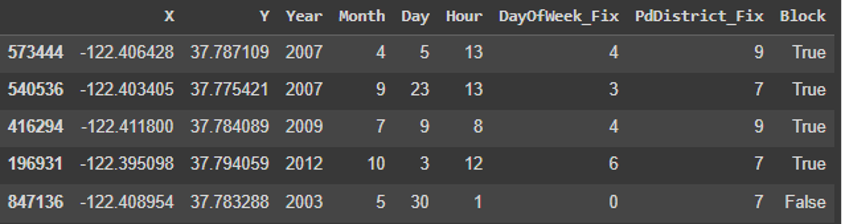
Given the analysis of each of the attributes, Date will be divided into Year, Month, Day and Hour since it can provide more performance to the model aspects such as what time of day certain crimes occur. The Description will not be used for training, DayOfWeek will be used, but changing the data type to int (Monday 0, Tuesday 1, etc) the district will not be taken into account because of the explanations given above. Resolution will also not be taken into account for the model. In the case of Address, we will search if the address contains the word “Block” and we will add a new column that will be boolean and if it contains it, it will have value True. X and Y will also be trained in the model. So it would be something like this before training them with models. In my opinion it was not necessary to use any kind of dimensionality reduction since they are limited attributes and many of them are difficult to understand (or useless). The correlation matrix did not give novel results against this table either.
1
2
3
4
5
dates = pd.to_datetime(train["Dates"])
train["Year"] = dates.dt.year
train["Month"] = dates.dt.month
train["Day"] = dates.dt.day
train["Hour"] = dates.dt.hour
1
2
3
4
5
6
7
8
le = LabelEncoder()
train["Category_Fix"] = le.fit_transform(train["Category"])
train["DayOfWeek_Fix"] = le.fit_transform(train["DayOfWeek"])
train["PdDistrict_Fix"] = le.fit_transform(train["PdDistrict"])
train['Block'] = train['Address'].str.contains('block', case=False)
train_data = train.drop(columns=["Category", "DayOfWeek", "PdDistrict","Dates", "Address", "Resolution", "Descript"])
Model
In this case, I selected two algorithms to focus on the analysis. I opted for a lazy learner that I assumed would not perform very well. However, since we are dealing with crimes involving geographical attributes, I found it interesting to note their performance. K-nearest neighbor (KNN) algorithms are usually sensitive to the spatial distribution of the data, so they could capture spatial patterns. On the other hand, I chose the Random Forest model. This algorithm is recognized for its ability to handle large data sets and its resistance to overfitting, which makes it promising for this particular case, where we have a significant amount of crime data with multiple attributes. Another not minor fact, that when doing my case studies this algorithm was always one of the best in terms of performance. Both models offer different approaches, which will allow us to evaluate how they perform in predicting crimes with geospatial characteristics, thus providing a more complete picture of predictive analytics in this context. To add, in case of Python add Logistic Regression to compare with these two
Results
Random Forest
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
from sklearn.model_selection import train_test_split
X_strat, _, y_strat, _ = train_test_split(
train_data.drop("Category_Fix", axis=1),
train_data["Category_Fix"],
stratify=train_data["Category_Fix"],
test_size=0.05, # Reduce the test set to 5%.
random_state=1
)
X_train, X_test, y_train, y_test = train_test_split(
X_strat,
y_strat,
test_size=0.5,
random_state=1
)
As for the Random Forest parameters, I achieved maximum performance with the parameters: 100 trees, gini index, and with a maximum depth of 15. I tested with different depth values, and at a lower value the accuracy dropped considerably, while raising it higher made the performance extremely bad (in some cases, it did not even improve the performance)
1
2
3
4
5
6
7
8
9
from sklearn.ensemble import RandomForestClassifier
random_forest_model = RandomForestClassifier(
n_estimators=60,
max_depth=32,
random_state=1
)
Accuracy train: 0.91399
Logarithmic loss: 0.444
Accuracy test: 0.5865
Logarithmic loss test: 5.8776
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
from sklearn.preprocessing import label_binarize
y_test_bin = label_binarize(y_test, classes=np.unique(y_test))
random_forest_model.fit(X_train, y_train)
y_scores = random_forest_model.predict_proba(X_test)
n_classes = len(np.unique(y_test))
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(n_classes):
fpr[i], tpr[i], _ = roc_curve(y_test_bin[:, i], y_scores[:, i])
roc_auc[i] = roc_auc_score(y_test_bin[:, i], y_scores[:, i])
plt.figure(figsize=(20, 16))
for i in range(n_classes):
plt.plot(fpr[i], tpr[i], label=f'Clase {i} (AUC = {roc_auc[i]:.2f})')
plt.plot([0, 1], [0, 1], 'k--')
plt.xlabel('Tasa de Falsos Positivos')
plt.ylabel('Tasa de Verdaderos Positivos')
plt.title('Curva ROC para cada clase')
plt.legend(loc='best')
plt.show()
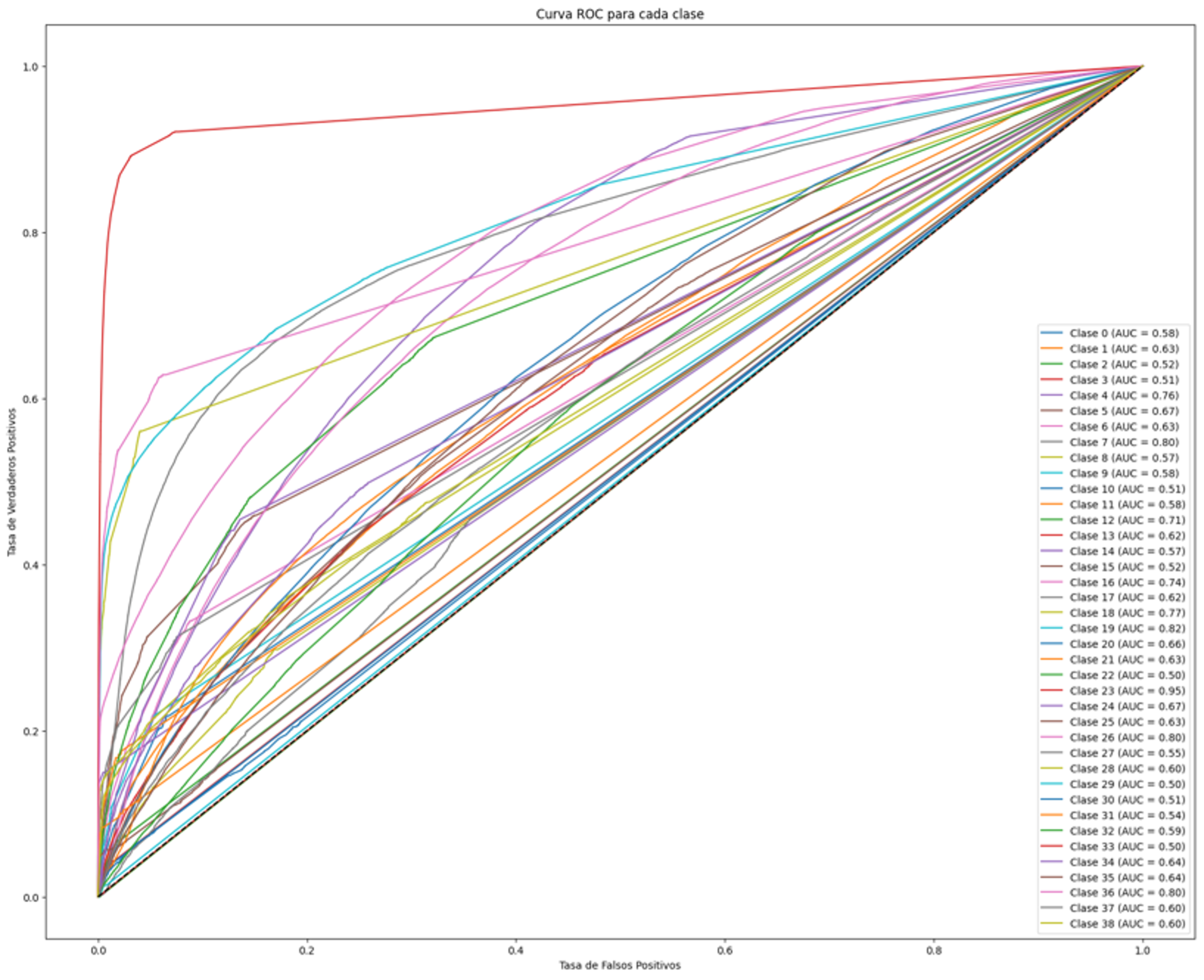
In the random forest model It is observed that the ‘Larency’ class has a considerable increase, accompanied by a much more favorable true positive ratio. In addition, subsequent categories show relatively high ratios of true positives and a low incidence of false negatives, positioning this model as the most effective so far.
KNN
1
2
knn_model.fit(X_train, y_train)
print(model_result(knn_model))
Accuracy train: 0.3415
Logarithmic loss: 1.627
Accuracy test: 0.1889
Logarithmic loss test: 15.114
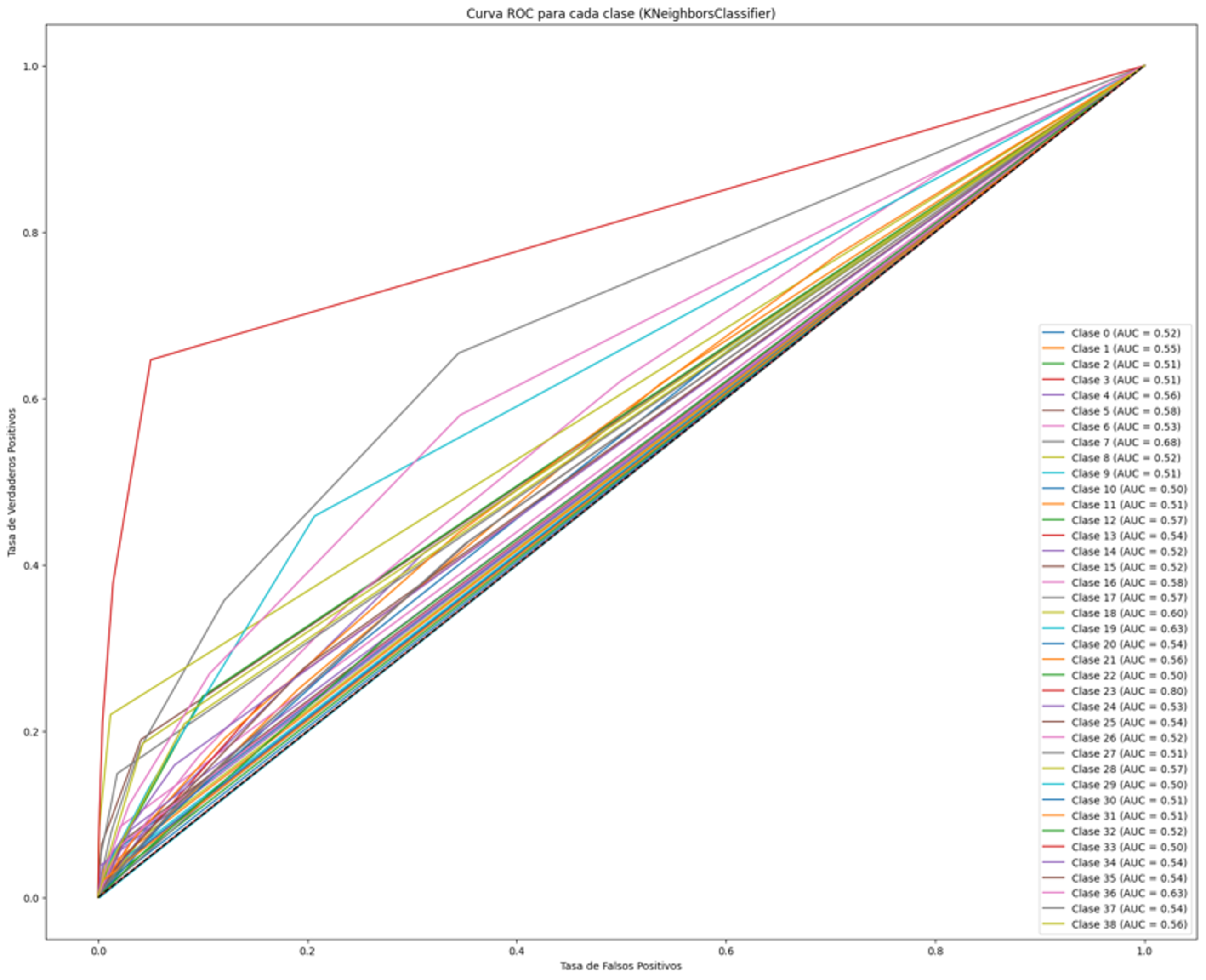
In this case we can see that there is one class that predicts a large number of true positives while the other classes accumulate a large number of false positives. This imbalance in prediction may be one reason behind the apparent 34% success in the overall accuracy metric. The fact that the model consistently predicted the “Larency” class as positive in most cases has caused the majority of true positives, which is positive. However, this biased prediction has also led to a significant number of false positives in other classes, which reduces the overall accuracy of the model.
Conclusion
The results obtained from the models show significant differences between Python and RapidMiner, with Python showing markedly superior performance. In Python, both Random Forest and KNN showed a significant improvement in accuracy, with Random Forest achieving 92% accuracy. These models classified categories better and showed higher true positive rates, especially in the dominant category, making them more effective models. In summary, the models implemented in Python significantly outperformed those implemented in RapidMiner, showing higher accuracy and classification capability. It is important to highlight the significant improvement of Random Forest in Python, achieving an accuracy close to 92%, which positions it as the most effective model for this particular dataset.